
.jpg){kind=link}
Im Juli des letzten Jahres haben wir „Future Audiences“ (zukünftige Zielgruppen) lanciert, eine neue Initiative der Wikimedia Foundation, mit der wir untersuchen wollen, wie wir den Bedürfnissen der kommenden Generationen derer, die Wissen suchen und Wissen verbreiten, weiterhin gerecht werden können. Mit diesem Post geben wir ein Halbjahresupdate zu unseren Erkenntnissen, die wir durch Experimente bis jetzt gewonnen haben, und zu unseren künftigen Zielen.
Wie werden zukünftige Generationen von Wikipedia lernen und zu Wikipedia beitragen? Wir wissen es noch nicht – aber durch kurze Experimente im Lauf des letzten Jahres hat die Wikimedia Foundation tiefere Einsichten dazu gewonnen, wie Wikipedia den Bedürfnissen der kommenden Generationen derer, die Wissen suchen und Wissen verbreiten, weiterhin gerecht werden kann, auch wenn die Technik und das Online-Benutzerverhalten sich weiterentwickeln. Lies hier weiter, um über unsere Erkenntnisse aus der ersten Runde an Experimenten (mit ChatGPT und sozialen Apps) und ein neues Experiment zur Online-Textauswertung, das wir auf der Grundlage dieser Erkenntnisse planen, zu erfahren.
Erinnerung: Was sind „zukünftige Zielgruppen“?
Die Mission der Wikimedia-Bewegung war es schon immer, allen Menschen auf der Welt freies Wissen bereitzustellen. Doch wir wissen, dass neuere technische Entwicklungen – darunter die Fortschritte bei Künstlicher Intelligenz, neue soziale Apps und Geräte, die uns neue Interaktionsmöglichkeiten mit der digitalen Welt geben – das Potenzial haben, die Rolle der Wikimedia-Projekte innerhalb des breiteren Informationsökosystems stark zu beeinflussen. Auch wenn unsere Mission die gleiche wie vor 20 Jahren bleibt, werden die Methoden, um sie zu erfüllen, sich weiterentwickeln müssen.
Zu diesem Zweck hat die Wikimedia Foundation im letzten Jahr einen neuen Arbeitsbereich namens „Future Audiences“ gegründet, eine Zusammenarbeit aus mehreren Teams, um zu untersuchen, wie wir zukünftige Zielgruppen aus Menschen, die Wissen suchen und beitragen, erreichen können.
Future Audiences dient nicht der Produktentwicklung, sondern soll zeitlich begrenzte Experimente durchführen, um Innovationsmöglichkeiten für die Wikimedia Foundation zu finden und zu empfehlen. Wenn ein Experiment vielversprechende Ergebnisse liefert, kann es dazu führen, dass die Wikimedia Foundation größere Investitionen in neue Produkte und/oder Ansätze zum Einbinden neuer Zielgruppen tätigt; andernfalls (wie mit unserem ersten Experiment, einem Wikipedia-Plugin für ChatGPT – mehr dazu unten) können wir zumindest schnell und ohne nennenswerte Belastung unserer Ressourcen wertvolle Erkenntnisse gewinnen.
Welche Experimente haben wir durchgeführt und was haben wir bis jetzt erfahren?
{kind=link}
1. Conversational AI: Mehr als nur ein Chatbot
Wir haben das Jahr mit den folgenden Forschungsfragen zu Entwicklungen im Bereich dialogbasierter KI-Systeme begonnen:
- Werden Online-Wissenssuchende dazu übergehen, Informationen von ChatGPT statt von Wikipedia zu beziehen?
- Wie gut ist ein dialogbasiertes KI-System darin, Informationen aus Wikipedia zu finden und zusammenzufassen?
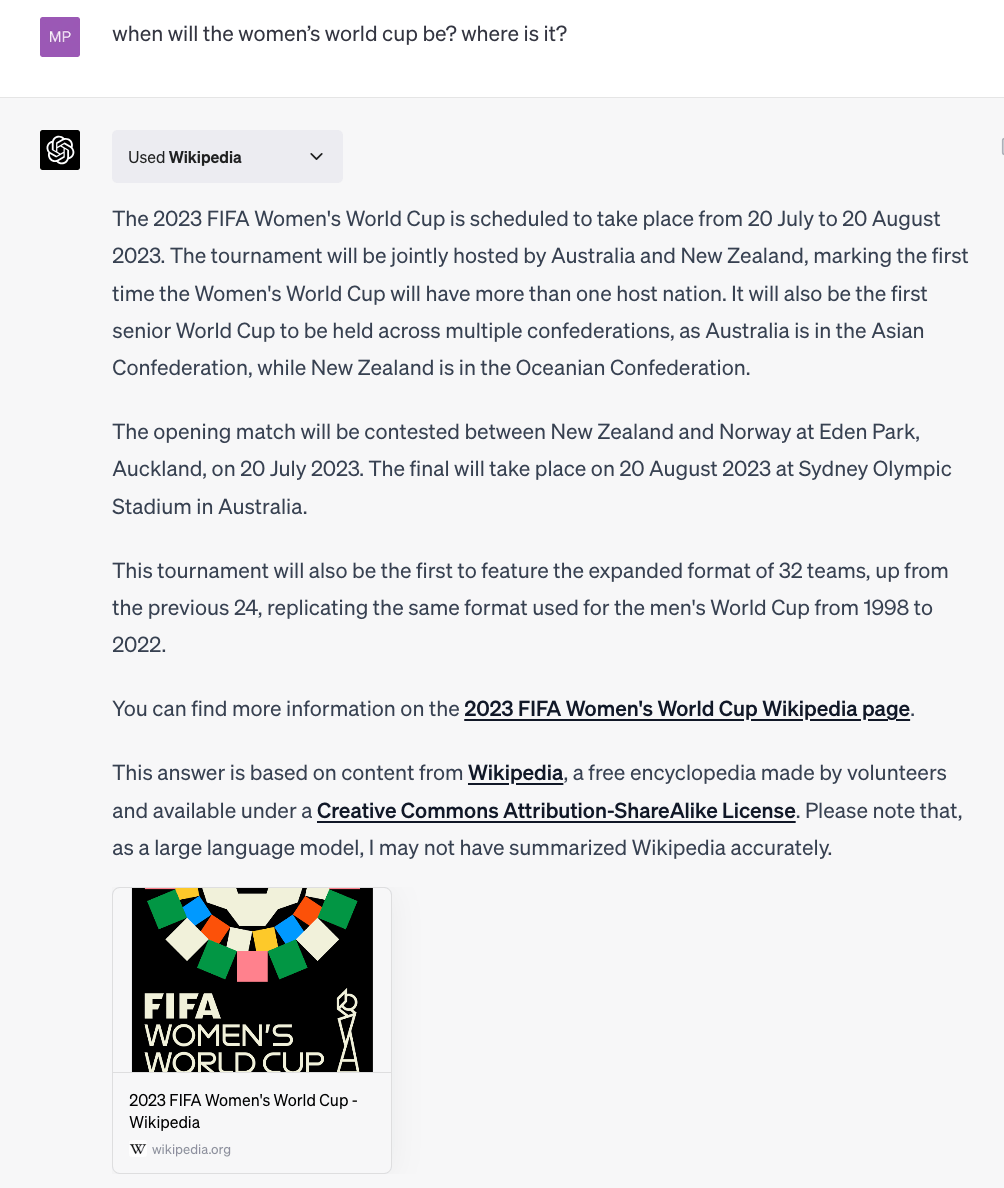
Unser erstes Experiment des Jahres war die Entwicklung eines Wikipedia-Plugins für ChatGPT, wodurch Benutzer:innen von ChatGPT Antworten auf allgemeine Wissensfragen direkt aus Wikipedia erhalten konnten (statt basierend auf den gesamten Trainingsdaten des Systems). Die Ergebnisse dieses Experiments haben uns gezeigt:
- ChatGPT ist nicht die neue Wikipedia – Wikipedia bleibt eine wichtige und verlässliche Online-Informationsquelle. Auf der Grundlage der Zugriffszahlen für Wikipedia im Lauf des Jahres sowie den Nutzungs- und Umfragedaten zu unserem experimentellen ChatGPT-Plugin haben wir geschlossen, dass Konsument:innen, auch wenn sie zur Nutzung von KI-Chatbots wie ChatGPT für die Informationssuche übergehen, diese zusätzlich zu – und nicht als Ersatz für – Wikipedia nutzen. Benutzer:innen unseres Plugins gaben an, dass sie weiterhin Wikipedia direkt besuchten und Informationen, von denen sie wussten, dass sie aus Wikipedia stammten, mehr Vertrauen schenkten.
- Dialogbasierte KI-Systeme können Wikipedia-Inhalte relativ gut (aber nicht perfekt) zusammenfassen. Auch wenn Menschen verständlicherweise vorsichtig sind, wenn sie Informationen von allgemeinen Chatbots wie ChatGPT beziehen, hat das Verfahren, mit dem wir unser Plugin erstellt haben (KI nutzen, um relevante Informationen auf intelligente Weise in einer bestimmten Wissensquelle wie Wikipedia zu finden und eine Zusammenfassung auszugeben, eine als Retrieval-Augmented Generation [RAG] bekannte Technik), Ergebnisse relativ guter, wenn auch nicht perfekter Qualität, geliefert.
Daher schließen wir, dass generative KI zwar eine wichtige Rolle dabei spielen kann, zukünftigen Zielgruppen die effizientere Nutzung von Wikipedia-Wissen zu ermöglichen, Chatbots allerdings nicht unbedingt die beste Methode sind, um das zu erreichen. Diese Erkenntnisse haben uns zu einem neuen Experiment mit KI geführt, Citation Needed (siehe unten).
2. Persönlichkeitsgetriebene soziale Apps: Ein neues Wiki-Phänomen?

{kind=link}
Auch wenn 2023 das Jahr von ChatGPT war, haben wir im Jahresbericht zu externen Trends einen weiteren zentralen Trend identifiziert: die zunehmende Vorliebe jüngerer Zielgruppen, Informationen nicht im Internet oder in Wikipedia zu suchen, sondern in persönlichkeitsgetriebenen sozialen Apps wie TikTok und YouTube. Diese Erkenntnis hat die folgenden Forschungsfragen ergeben:
- Könnte die Weiterverarbeitung von Wikipedia-Inhalten zu besser für soziale Apps geeigneten Formaten Informationen für jüngere Zielgruppen ansprechender machen?
- Gibt es in diesen Apps Ersteller:innen von Inhalten, denen an der Verbreitung verlässlicher Informationen und Inhalte aus Wikimedia-Projekten gelegen ist?
Durch qualitative Forschung (Umfragen, Interviews und Nutzbarkeitsstudien mit Konsument:innen und Ersteller:innen von Inhalten über die Apps) haben wir Folgendes erfahren:
- Jüngere Zielgruppen sind gegenüber Online-Informationen skeptischer eingestellt und bevorzugen es, von Menschen statt von unpersönlichen Websites zu lernen. Auch wenn das Format, in dem Informationen präsentiert werden, definitiv wichtig ist, um ihre Aufmerksamkeit zu erregen (sie bevorzugen üblicherweise kürzere, multimediale Erfahrungen gegenüber langen Texten), ist es auch sehr wichtig, von wem die Inhalte stammen. Das könnte eine Chance für Wikipedia sein, um sich selbst dieser Zielgruppe, die ebenfalls ein Interesse an verlässlichen Informationen hat, deutlicher zu präsentieren.
- Es gibt eine Community von „Wissensschaffenden“, die auf Apps wie TikTok Fakten und Bilder aus Wikimedia-Projekten verbreiten und ein großes Publikum erreichen. Diese Menschen teilen verlässliche Informationen zu Themen, die sie begeistern, mit anderen, und sie nutzen Wikipedia als Ressource für die Erstellung von Inhalten. Auch wenn sie kein Interesse daran haben, direkt zu unseren Projekten beizutragen, haben wir eine Chance, zu untersuchen, wie wir diese Menschen einbinden, um uns dabei zu helfen, freies Wissen auf innovative neue Arten zu verbreiten und jüngere Generationen weltweit zur Wikimedia-Bewegung einladen.
Was machen wir als Nächstes?
Neues Experiment: „Citation Needed“
Da der digitale Raum zunehmend von Falschinformationen überspült zu werden droht, untersuchen wir, ob KI genutzt werden kann, um Lesenden zu helfen, mithilfe von Wikipedias Wissen die Verlässlichkeit der online konsumierten Informationen zu verstehen.
Citation Needed (benannt nach der in der englischsprachigen Wikipedia weitverbreiteten Vorlage zur Markierung unbelegter Sätze in Artikeln) ist ein neues Experiment zu diesem Zweck. Durch eine experimentelle Erweiterung des Chrome-Browsers, die Funktionen großer Sprachmodelle nutzt, erhalten Benutzer:innen die Möglichkeit, Inhalte, die sie online lesen, schnell mit Inhalten in Wikipedia abzugleichen. Die Erweiterung wird Benutzer:innen Informationen dazu geben, ob eine ausgewählte Aussage durch Informationen in Wikipedia gestützt wird oder nicht und wie viele Belege in dem Artikel genutzt werden, wie viele Menschen an dem Artikel gearbeitet haben und wann der Artikel zuletzt bearbeitet wurde. Wie bei unserem ersten Experiment mit generativer KI werden wir auch wieder erfassen, wie gut KI im Rahmen dieser Funktion Informationen aus Wikipedia suchen und zusammenfassen kann. In den nächsten Monaten wird Citation Needed für interessierte Benutzer:innen zum Testen bereitstehen und wir werden die Nutzung und das Feedback auswerten.
Wenn du mehr über Citation Needed erfahren und beim Testen helfen möchtest, kannst du auf der Projektseite im Meta-Wiki mehr Details finden.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation