
L’interconnessione tra Wikipedia e Wikidata è ora più ampia che mai.
Il Wikipedia Citations dataset include attualmente circa 30 milioni di citazioni da pagine di Wikipedia a una varietà di fonti, di cui 4 milioni di pubblicazioni scientifiche. L’aumento della connessione con data services esterni e la fornitura di dati strutturati a uno degli elementi chiave degli articoli di Wikipedia ha due vantaggi significativi: innanzitutto, una migliore individuazione degli articoli enciclopedici rilevanti relativi a studi accademici; inoltre, il rafforzamento di Wikipedia come autorità sociale e hub politico, che consentirebbe ai responsabili politici di valutare l’importanza di un articolo, di una persona, di un gruppo di ricerca e di un’istituzione osservando quanti articoli di Wikipedia li citano.
Queste sono le motivazioni alla base del progetto “Wikipedia Citations in Wikidata”, sostenuto da un finanziamento della WikiCite Initiative. Dal gennaio 2021 fino alla fine di aprile, il team di Silvio Peroni (co-fondatore e direttore di OpenCitations), Giovanni Colavizza, Marilena Daquino, Gabriele Pisciotta e Simone Persiani dell’Università di Bologna (Dipartimento di Filologia Classica e Italianistica) ha ha lavorato allo sviluppo di una codebase per arricchire Wikidata con citazioni a pubblicazioni accademiche che sono attualmente referenziate in inglese in Wikipedia. Questa base di codice si articola in quattro moduli software in Python e integra nuovi componenti (un classificatore per distinguere le citazioni in base alla fonte citata e un modulo di ricerca per dotare le citazioni di identificatori da Crossref o altre API). In tal modo, Wikipedia Citations estende il lavoro precedente che si è concentrato solo su citazioni già dotate di identificatori.
Nei primi due step del workflow (extractor e converter) è stata implementata la mappatura tra i vari modi in cui le citazioni di Wikipedia sono rappresentate negli articoli di Wikipedia e l’OpenCitations Data Model (OCDM) e poi arricchita con una componente preposta a trovare nuovi identificatori di entità in un dataset compatibile con OCDM (enricher), mentre nella fase pusher è stata abilitata la mappatura tra OCDM e Wikidata e il codice è stato infine rilasciato in GitHub.
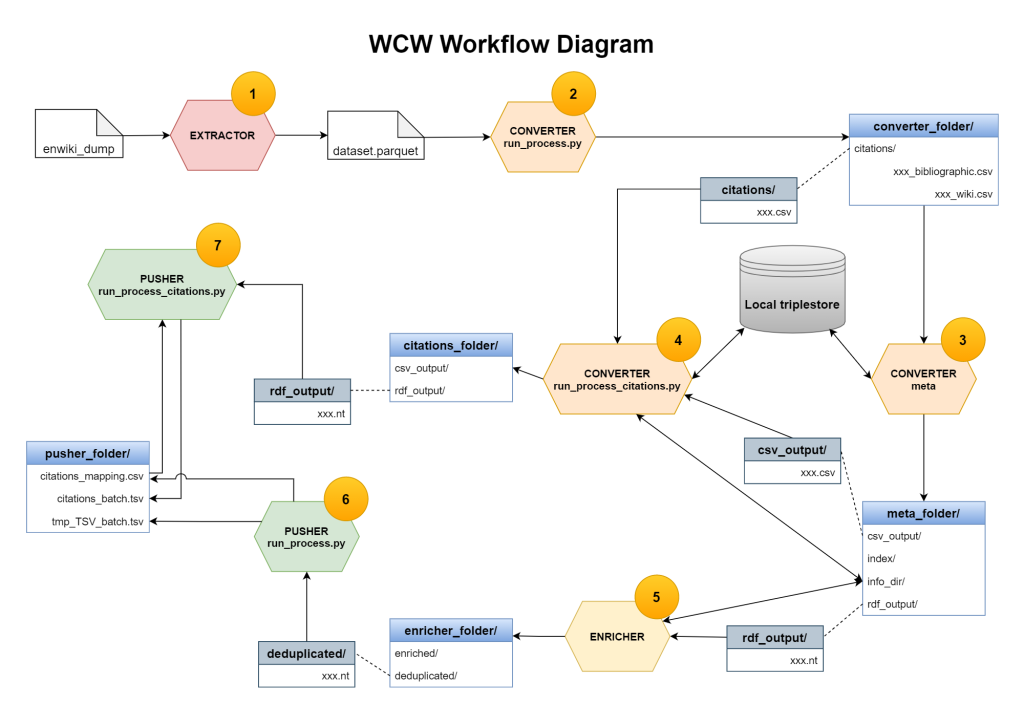
L’ampia documentazione che ha accompagnato il rilascio del codebase è cruciale per uno degli obiettivi principali del progetto, ovvero l’adozione e il riutilizzo del codebase da parte della comunità in altri progetti Wikimedia rilevanti, mentre l’impegno di varie comunità (Wikidata, biblioteche, studiosi…) è favorito da un lato fornendo un maggior numero di dati sulle citazioni inclusi in Wikidata, dall’altro attraverso la comunicazione su blog e condividendo gli aggiornamenti su Twitter e mailing list pubbliche
Questo progetto, il cui scopo ambizioso è quello di rendere maggiormente individuabili i contenuti di Wikipedia e arricchire Wikidata con un corpus pronto all’uso per ulteriori analisi o per lo sviluppo di nuovi servizi, è aperto a prospettive future. L’intenzione è quella di utilizzare il software per creare un dataset di citazioni in inglese di Wikipedia per capire, in particolare, quante nuove entità (cioè, citazioni di pagine di Wikipedia, articoli e luoghi citati, autori) dovrebbero essere aggiunte a Wikidata per caricare il set di citazioni estratte, con il risultato di aggiungere al dataset un’enorme quantità di nuove entità legate alla bibliografia.
I primi passi sono stati fatti, ora puntiamo ad estendere il coinvolgimento della comunità accademica, in particolare quegli studiosi che fanno leva su Wikidata nei servizi esistenti, e ad interagire con ricercatori, biblioteche e istituzioni interessate ad un nuovo approccio alla ricerca, incentrato sulle persone (dagli individui ai gruppi di ricerca) e il loro valore intellettuale.