The Internationalisation/Localisation (i18n/l10n) team at the Wikimedia Foundation works on a set of tasks every two weeks. The following describes the work we’ve done over the past month.
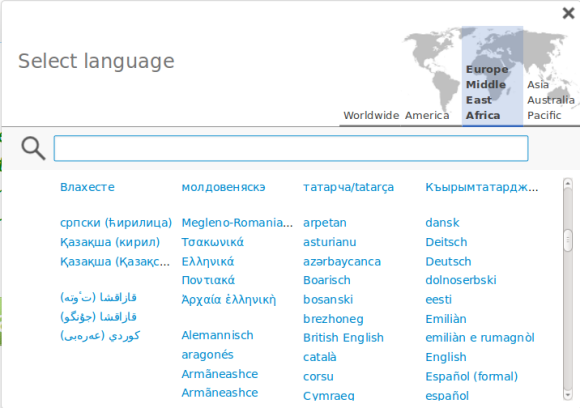
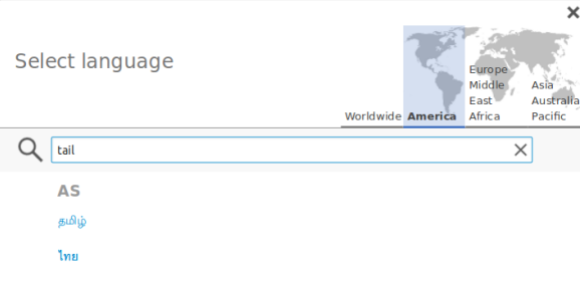
We’ve worked on making the Universal Language Selector (ULS) functional according to the design prototypes, and it is now available for alpha testing on http://translatewiki.net. Please help us test it in your language. The features listed below are the highlights from the development work done on the ULS:
- Supporting approximate search, which will give results even with typos in it.
- Ability to do language search using any language: Search using the translation of language names in other language names.
- Auto-complete for search across languages.
- Writing systems that belong to the same family are visually grouped together.
Another focus of our work has been Project Milkshake, an effort to release our existing internationalisation-related JavaScript components as standard jQuery libraries. These libraries —dually licensed under GPL and MIT license— will not only help us in integrating our tools better with the Universal Language Selector, but will also let other people reuse them widely in other web projects, and get the benefits of internationalisation components just by using these libraries:
- jquery.i18n — A library to provide full i18n framework that supports parameter replacements and grammar-, plural-, and gender-dependent translations;
- jquery.webfonts — A library to provide webfonts support, developed from WebFonts extension;
- jquery.ime —A library to provide input methods in the browser, developed from Narayam extension;
- jquery.uls will also be available soon as we make more progress on ULS.
We continued to improve translation user experience by making the screens more user-friendly and making the process more efficient for translators. We are currently working on the prototypes. This aims to increase the number of translators, as well as provide an interface that helps them spend their time as efficiently as possible. In the coming weeks, we will perform in-depth usability tests with several members of the community. You can learn more about them at the Translation UX page and, if you are interested, consider volunteering to participate in the usability tests.
As usual, apart from these, we continued fixing issues that were reported in Bugzilla, as well as translation-related issues in translatewiki.net. Narayam, the input tool, was deployed in Bengali Wikisource. If you need Narayam / WebFonts enabled on your wiki, please open a bug in bugzilla.
In the coming weeks, we will be working on integrating Narayam and WebFonts as part of language tools in Universal Language Selector, completing the translation UX improvements.
We will also be having our monthly online office hours on August 15 16:30 UTC (8:30 PDT). This is an opportunity to ask the development team questions about current and upcoming i18n features. The team will also share updates on exciting work happening on the ULS, translation workflow enhancements and additional language support on Narayam and Webfonts.
Please feel free to contact us through the mediawiki-i18n mailing list.
Srikanth Lakshmanan, Internationalisation/Localisation Outreach / QA Engineer
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation