
Over the last years, Wikimedia engineers have built significant Node.js services to complement the venerable MediaWiki wiki platform implemented in PHP. Over 10 such services are deployed in our production environment, powering features like VisualEditor, scientific formulae rendering, rich maps display and the REST content API. Individual services are built and owned by specific teams on top of the overall Node.js platform, which is maintained by the Wikimedia Services team. Recently, we upgraded our infrastructure to Node.js v6. This blog post describes how we did it, and what we learned in the process.
Upgrade to Node 6
In large production environments, it is vital that you can trust the stability and security of your infrastructure. While early upgrades (starting with 0.8) had a fair amount of API churn and regressions, Node has come a long way with each subsequent release thanks to the hard work and maturity of the community. The first LTS (long term support) release (Node 4) was the best so far, from our perspective. Naturally, we were curious to find out whether this trend would continue for the first upgrade between official LTS releases.
Looking at the changelog, the most exciting changes in Node 6 LTS looked to be v5.1 of the v8 JavaScript engine, which (in addition to 5.0 changes) offers various language improvements and now supporting over 90% of ES6 features. We are especially excited about the incorporation of several components of the new “Orinoco” garbage collector and the native integration with Chrome’s debugger.
Before we roll out a new version to production, we naturally need to run thorough tests to catch regressions, ascertain compatibility, and characterize expected performance changes. Node 6 was no exception.
Compatibility
The first step was to assess the effort needed by our developers to port the services to Node 6. We found that Node v6 provides the highest level of compatibility of all Node releases we have used thus far. For all but one service, all that needed to be done was to recompile the services’ binary node module dependencies.
Performance
At scale, performance regressions will be noticed quickly by users, and can easily translate to outages. Cost is also a consideration, as our highest traffic node services run on clusters with 16 – 24 servers per datacenter. Performance testing is thus a mandatory part of upgrade preparations.
As a first pass, we ran throughput tests on our most performance-sensitive services. For the Parsoid wikitext processing service, we saw median latency for converting a specific page to HTML drop by about 5%, and (more remarkably) peak memory consumption drop by 30%. Similarly, RESTBase saw a 6% throughput improvement. There were no performance regressions, so we felt comfortable proceeding to longer-term functional testing in staging.
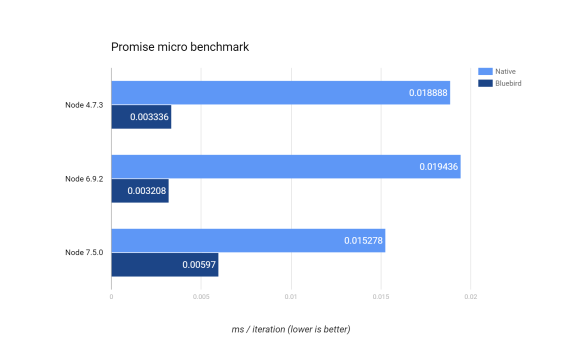
Native Promises still slow
All our services are using Promises to organize asynchronous computations. In previous profiling, we identified V8’s native Promise implementation as responsible for significant portions of overall service CPU time & allocations, and have since used the highly optimized Bluebird implementation for our Promise needs. Curious about Node 6 changes, we re-ran a micro benchmark based on an asynchronous stream transformation pipeline, and found that native Promise performance is still around six times slower than Bluebird. Looking ahead, the V8 team has made some inroads in Node 7.5.0 (with V8 5.3), but is still trailing Bluebird significantly. In a brief exchange we had with the V8 team on this topic last year, they mentioned that their latest efforts are towards moving Promises to C++, and this work has since made it into the tree. We will revisit this benchmark once that code is available in Node.
Staging environment
With the confidence provided by compatibility and performance benchmarking, we proceeded at thoroughly testing each of them, first locally and then left them running in our staging environment for a while. This environment is set up to closely mirror our production site allowing us to monitor the services and look out for regressions in a more realistic manner. As none were spotted, we decided to upgrade the clusters running Node.js services one by one over the course of several days at a rate of one per day.
Deployment
In our production environment, we have several clusters on which all of these services are running; most are homogeneous and host only one service per cluster, while one is designated as the miscellaneous cluster hosting 9 stateless Node services.
Thanks to the good compatibility between Node v4 and Node v6, no code changes were needed. Right after upgrading the services, we saw an instant decrease in memory consumption of up to 50%. We routinely measure heap usage for all services using service-runner—a generic service supervisor library in which we have abstracted common services’ needs, such as child processes monitoring, configuration management, logging, metrics collection and rate limiting. The following figure shows the amount of memory consumed per worker for the Change Propagation service.
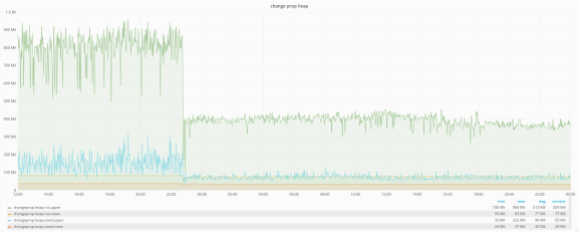
The green line shows the amount of peak RSS memory consumed by individual workers. On the left-hand side of the graph (until around 23:00 UTC), we have the memory consumption while running on Node v4.6.9; the average peak memory fluctuates around 800 MB. After switching the service to Node v6.9.1, one can see the maximum amount of memory being halved to approximately 400MB. That steady amount of memory implies that workers are respawned less often, which contributes directly to the service’s performance.
Conclusion
Node 6 really delivered on stability and performance, setting a new benchmark for future releases. During the upgrade we encountered no compatibility issues, and found no performance regressions to speak of. The V8 Orinoco garbage collector work has yielded impressive memory savings of up to 50%. As a consequence, strong heap pressure has become rare, and latency for our most demanding services has become more predictable.
Combined with our shared library infrastructure and deployment processes, we are in a good spot with our Node platform. This lets our engineers focus on delivering reliable features for users, and minimizes time spent on unexpected issues.
Marko Obrovac, Senior Software Engineer
Petr Pchelko, Software Engineer
Gabriel Wicke, Principal Software Engineer
Services team, Wikimedia Foundation
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation