A blog post by Sandra Fauconnier, with contributions by Sam Donvil (PACKED) and Joris Van Donink (Jakob Smitsmuseum). This blog post describes a GLAM pilot project for Structured Data on Wikimedia Commons, executed by PACKED, and mentored by Sandra. We hope this will inform and inspire Wikimedians who want to learn about structured data, and/or (intend to) do similar GLAM-Wiki collaborations!

The Jakob Smitsmuseum is a small municipal museum in Mol, Belgium. It was founded in 1977, and is currently run by 1.5 full-time staff, supported by 9 members of the ‘Friends of the Jakob Smitsmuseum’ association. The museum’s collection is dedicated to the work and life of painter Jakob Smits (1855–1928) and his contemporaries, the so-called ‘Molse School‘ (‘School of Mol’), a loose 20th-Century art movement of painters in the Campine (‘Kempen’) region in Flanders.








Jakob Smits grew up, and started his artistic career, in the late 19th Century in the Netherlands. Inspired by other ‘movements’ of rural painters who worked outdoors or ‘en plein air’ (such as Smits’ colleagues and friends of the Hague School), he moved to the Campines region, where he portrayed rural life in all its aspects: farmers’ lives, villages and landscapes. In the early 20th Century, Smits became an influential painter in the region around Mol, inspiring many other artists, and leaving behind a large oeuvre of paintings which have been collected by various European museums. Many of his works can still be seen at the Jakob Smitsmuseum.

The museum website of the Jakob Smitsmuseum contains a section on collections which currently only shows general information, not a database of the specific works collected by the museum. Most small museums have some kind of internal system to keep track of their collections, accessible by staff and volunteers. But publishing an entire collection online for the broad public is not cheap or easy. This is why you will rarely see small cultural institutions’ websites that have extensive online collection databases.
So, how can the Wikimedia ecosystem help a small museum to make its collection useful and visible online?
The Jakob Smitsmuseum decided to publish its collection’s data as Linked Open Data on Wikidata, and the corresponding images on Wikimedia Commons. It was helped in this process by PACKED, a Belgian centre of expertise in digital heritage. PACKED has already supported many Flemish and Brussels-based cultural institutions in publishing their collections on Wikimedia platforms, and invests in this for a variety of reasons:
- Collections included in Wikimedia platforms gain increased visibility; they become easier to discover via search engines and voice assistants.
- Wikimedia volunteers help with enriching and describing the collections, often adding quite valuable additional information and translations.
- The Wikimedia ecosystem offers a free infrastructure to publish collections as Linked Open Data, which is especially valuable for organizations that don’t have the capacity to do this themselves.
- Collections on Wikimedia platforms become easy to re-use across the web, in various applications, and of course in Wikipedia articles.
For now, the Jakob Smitsmuseum and PACKED have only contributed data and images of the works by Jakob Smits himself. The museum also collects works by Smits’ contemporaries, which they intend to contribute to Wikimedia platforms at a later stage, when the rights for these works have been cleared.
The upload process
In March 2019, PACKED has created Wikidata items (query) for the artworks by Jakob Smits in the museum’s collection. Adding data about art collections to Wikidata has become a common part of the workflow of GLAM-Wiki projects. By publishing that data on Wikidata, as described above, the data becomes multilingual, discoverable and re-usable across the web, and it can easily feed worklists, for instance to serve as inspiration for Wikipedia articles, or to invite further enrichment, like in this example for Asian Month 2019 by the Metropolitan Museum of Art.

In July 2019, PACKED uploaded the images of these artworks to Wikimedia Commons – at that point with the Pattypan upload tool, still describing the files in wikitext, but pointing to the Wikidata items in the information templates of the files.

{kind=link}
{kind=link}
{kind=link}
In October-November 2019, after the deployment of structured data statements on Wikimedia Commons, Sam and I have proceeded to add structured data to those files, and other community members have chimed in as well. The structured data of that same file (now) looks like this. (Please note: work in progress! The consensus on how to describe such files may change in the future!)

Thanks to the work of volunteer User:Jarekt, templates to describe images of artworks on Wikimedia Commons can now be vastly simplified if those images are enriched with structured data. The intricate Artwork template of the example above can now be replaced with a very simple {{Artwork}} (indeed: you don’t even need to enter the Q number of the artwork’s Wikidata item!), upon which the information in the file page will be pre-filled with relevant data from Wikidata and structured data on Commons. This is work in progress – there is not yet a settled community consensus, for instance, on how to describe the various types of sources for (GLAM) files. Please contribute to these discussions at Commons:Structured data/Modeling/Source and its talk page, and provide input about improvements to the Artwork template on the template’s talk page. This is a very new community process, and your ideas are much needed!

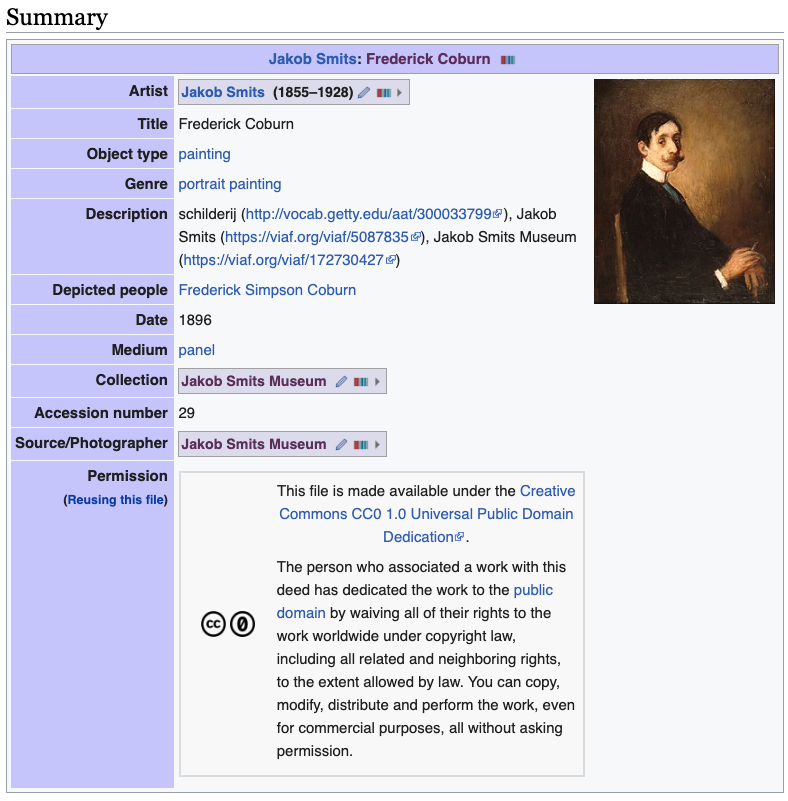
{{Artwork}} template simplification by User:Multichill. Note that it is not necessary anymore to include the |wikidata= parameter in the Artwork template if the file’s structured data (see example above) correctly points to the artwork’s Wikidata item.This example demonstrates an interesting challenge specific to GLAM content, which becomes clear now that structured data can be added to files. Where to place which data? On Wikidata and/or on Wikimedia Commons? At first sight, for anyone who browses Wikimedia Commons, it is obvious that the above mentioned image depicts a man with a moustache, and – with a bit more research – that he is the Canadian painter Frederick Coburn. But in fact it is a two-step process: the file depicts a painting, and that painting depicts Coburn! The latter bit of information is, in many cases, stored on Wikidata, describing the creative work – not on Wikimedia Commons, which contains the file that shows this artwork. Should this information be duplicated? Is duplication bad? What if the information gets out of sync on both websites?

{kind=link}
In an upcoming blog post, I will discuss this challenge in more detail. In any case, the Wikimedia community’s thought process about these issues has only just started, and it is a participatory process. If you have questions about this issue for now, or would like to contribute to ongoing discussions: visit the data modeling pages on Structured Data on Commons, and ask your questions on the talk page there.
Presenting small art collections in an interesting way: dynamic galleries on Wikimedia Commons
After the uploads to Wikidata and Wikimedia Commons, I have created an experimental, simple, dynamic and Wikidata-driven gallery on Wikimedia Commons of the work of Jakob Smits, grouped by the art collection that each work is held in. Such galleries can be created with the volunteer-built Listeria tool and {{Wikidata list}} template, enhanced with a so-called styled ‘row template’.

I have also created a gallery of the collections of the Jakob Smitsmuseum – in fact a ‘mini’ collection website on Wikimedia Commons!

Galleries on Wikimedia Commons are an interesting phenomenon. They are curated selections of files, usually created by hand by volunteers. Many of them tend to be subjective, and get out of date quite quickly. But the format is interesting: more than category views of files, they have the potential to display and highlight the most interesting content that is available on Wikimedia Commons, presented in an attractive way that end users are familiar with from other image-centric websites like Flickr and Pinterest. Wikidata and structured data open up the possibility to make galleries much more interesting and useful on Wikimedia Commons: it becomes possible, like in the examples above, to create ‘smart’ galleries that are always up to date, according to specific rules, such as ‘all paintings from collection x, ordered chronologically’, or ‘the 20 most recently uploaded photos of lobsters with ‘valued image’ assessment’. It is still undecided which software will be developed for Wikimedia Commons after basic structured data support; but I think that more advanced support for curating galleries definitely deserves consideration. In combination with advanced and refined search features, they make Wikimedia Commons more useful for more people, and certainly more relevant for content and GLAM partners.
Other outcomes
Statistics of impact and use
For cultural institutions, it is important to be able to see and demonstrate the impact of their materials on Wikimedia projects; and it is also very helpful if they can clearly see the activity (edits, improvements, translations) around them. At this moment, several external tools make it possible to see this impact and enrichment. The GLAMorous tool shows that more than 23% of the images from the Jakob Smitsmuseum are used in Wikipedia articles (and nearly 100% to illustrate Wikidata items). The GLAMorgan tool shows that these images have been viewed over 13,000 times in October 2019 on Wikimedia sites. Finally, the SPARQL_rc tool provides some flexible analysis of edits on Wikidata on the museum’s data items, showing who edited the items, and which changes were made over a given period of time. All these helpful tools are built and maintained as prototypes by Wikimedia volunteer Magnus Manske, but a more integrated and sustainable metrics infrastructure for content partnerships certainly needs attention in the future.
Visualizations and enrichment
GLAM collections on Wikidata can benefit from the very diverse sets of tools and interfaces that are available to gain insights in the data, visualize it, and help volunteers to enrich it. A few examples:



And here is a visualization of the topics that Jakob Smits depicted in his work. Check this Wikidata query for an up-to-date view.
Questions?
This blog post is part of a series about Structured Data on Wikimedia Commons and GLAM; more posts will be published in the upcoming weeks. See also the earlier general blog posts about Structured Commons by Keegan Peterzell.
Is this example and pilot project helpful for you? Does anything need further explanation? Feel free to ask questions here on Wikimedia Space, or on the general or data modeling talk pages of Structured Data on Commons.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation