Summary
In the first month of the humaniki project, we laid the groundwork for responsibly co-designing the new tool. We made progress a) in user research, conducting interviews with a total of 19 diversity-focused editors, community members, and researchers; and b) in software development, defining data-schemas and interface-guidelines for an extensible version of the humaniki tool.
User Research

How might we provide actionable statistics for diversity-focused editors and community members to improve content knowledge gaps on Wikimedia projects?
Following a user-centered design approach, we started our research inquiry by identifying our community stakeholders: users of the WHGI and Denelezh tools, diversity-focused editors, and leaders from several diversity organizations such as Women in Red, WikiDonne, Wiki Gap, WhoseKnowledge, and Art+Feminism.
In September, we completed participant recruitment as 13 diversity-focused editors and 12 community leaders signed up for interviews, along with a further 22 agreeing to lighter survey-based participation. We also started our generative research by interviewing 19 different users (as of October 7). Clearly, a lot of Wikimedians consider the biography knowledge gap awareness as an important factor to inform their Wikimedia activities.
In the interviews with editors, we conducted classic co-design activities like open card sorting where they suggested new diversity statistics that should be tracked along with ways in which current statistics can be made more usable. On the other hand, when speaking with technical experts, we focused on discussing potential integrations with existing diversity tools to bring coherence in different initiatives. For example, enabling data integration with several other projects like WikiGap and Listeria bot. Additionally, our conversations with researchers from gender and ethnic studies background helped us inform our interface guidelines in better presenting data about underrepresented groups. For example, uncollapsing the ‘non-binary’ gender category in the LGBTQIA use case.
We plan to aggregate all of our findings and insights from these interviews into design recommendations that will help us develop humaniki. We plan to release these findings in a report to inform future development efforts in the community even after our software development is complete.
Base Site Updates
We sketched out preliminary UI designs for humaniki that were a combination of the previous websites along with cues taken from a backlog of community feedback.
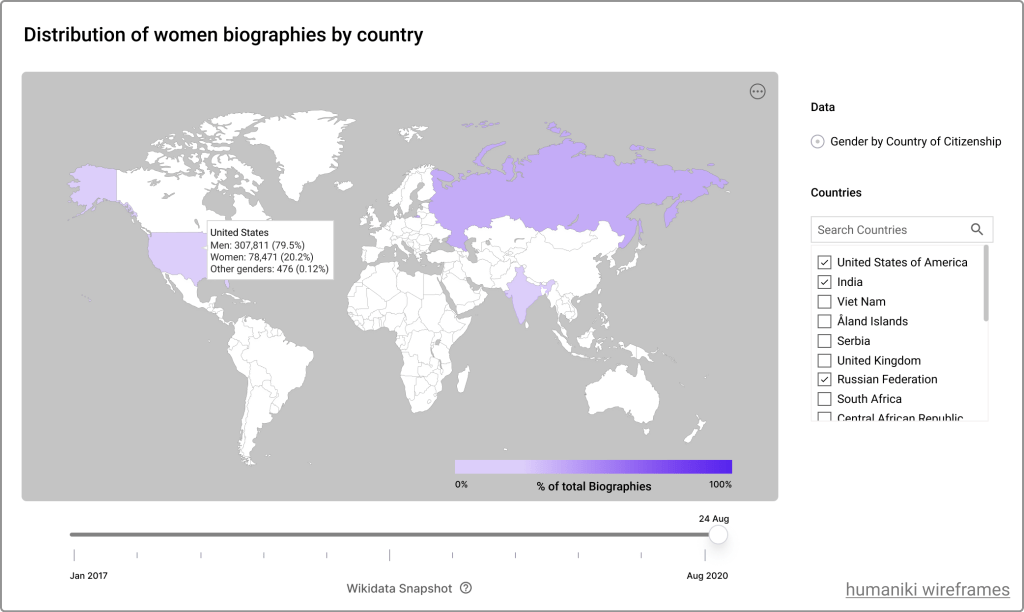
For instance, one of the proposed design changes in the data visualizations is to provide users the flexibility to select sub-categories of data, i.e. a comparative view of subsets of countries while interacting with gender by country map (see Figure 1). Updates like these will give users more autonomy over understanding trends in data about humans on Wikimedia projects. Another idea is to allow the user to scroll backward in the Wikidata snapshot that is used. These changes will help us meet user needs from different wikiprojects with different goals. For example:
- Wikiprojects with a focus on improving content diversity from a particular group of countries like WhoseKnowledge would be able to compare the gender gap between a subset of countries to inform their initiatives.
- Wikiprojects can also track the temporal coverage of content gaps on Wikimedia projects by switching between different periods using sliders while interacting with diversity metrics.
(Note: These designs might get updated based on the current design research in progress)
Technical Updates
In addition to the user-interface, a core part of humaniki is to re-architect data collection to support the smooth integration of more metrics and lists. In October, we worked on the
- merging of the technical stack of WHGI and Denelezh. A key point here was to define a new schema, which is publically viewable here for anyone interested in details.
- The updated data pipeline would reduce future efforts in tracking new properties, facilitate easy evolution comparisons, and support advanced computations like detecting mass deletion events.
Interested in participating?
We are still accepting survey responses for future research purposes and looking for community members interested in providing inputs for the project. Please sign up here if interested – survey link.

Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation