The stage is set
Wikidata Query Service, or WDQS, is a tool already familiar to the community. By leveraging the capabilities of Wikidata and SPARQL, anyone can extract relevant information from a vast graph of knowledge. Wikidata isn’t the only Wikimedia project that provides well structured data, though.
Enter Structured Data on Commons, SDC for short. SDC is a well defined structure that allows the community to assign extra metadata to each Wikimedia Commons object. Properties like depicts or author are useful when it comes to, e.g., categorisation.
Since SDC uses the same data structure as Wikidata, the idea of adding the Commons metadata to WDQS started to circulate quite quickly.
No easy solutions
Ok, since SDC and Wikidata are compatible, why not just drop all the SDC data into WDQS and call it a success? The answer is simple: performance. As you can guess, the Wikidata dataset is humongous–it currently contains about 11.5 billion statements! SDC is no slouch either, standing now at 1.2 billion statements and growing fast. Dataset size is a major contributor to the performance issues we are now resolving in WDQS. Adding a large amount of new data on a daily basis will only make things worse.
At this moment we do not have a good solution to that problem. We are researching and experimenting with different approaches, but the actual solution is far off. Fortunately, we can create a new service for SDC.
Stronger together
Having a separate SPARQL service, containing only SDC data, isn’t as helpful as it initially sounds. Sure, you can query the data, but SPARQL thrives on graph data – which SDC data only barely qualifies as. While properties like depicts link objects together, paths created that way are short and only allow for very basic inferences.
Fortunately for us, along came a feature of SPARQL known as federation. In simple words, federation allows users to seamlessly link graph data from many different SPARQL endpoints. WDQS itself allows for some interesting federations, like the UK’s National Statistics or the Dutch National Library. From the SDC perspective, federation would allow users to find Commons objects using the Wikidata knowledge graph. Note that, as mentioned before, SDC and Wikidata are compatible – e.g., SDC depicts statements point to valid entities in Wikidata.
One thing to bear in mind is that federation does have its limitations. Since underneath we are transporting vast amounts of data across the network, if we do federations on large datasets, they are unlikely to perform well.
Make it so
With that extremely long introduction we’d like to present to you Wikimedia Commons Query Service (WCQS for short). It’s a SPARQL service, operated similarly to WDQS, but with a few differences.
WCQS supports federation to the WDQS endpoint. Unfortunately, the opposite direction isn’t possible at the moment; we don’t have a solution yet for federating from WDQS to authenticated services.
Importantly, the service is in beta status right now. That means a few things:
- It’s prone to unscheduled and unannounced outages.
- No performance-related work (like scaling or load balancing) has been done yet.
- Some features are incomplete, like autocomplete (it’s working only on Wikidata properties/entities).
- Data reload is done weekly, so WCQS is always a bit out of date. Fortunately, it no longer requires any downtime.
- The service is located within the Wikimedia Cloud environment. This affects the way we are handling authentication for WCQS.
The last statement may have raised some eyebrows, since WDQS doesn’t use any form of authentication. It’s present in WCQS and we require a Wikimedia account. We added authentication mostly to be able to limit the impact of heavy-hitting users/bots on the service, as a last resort. Note that the current solution for authentication isn’t perfect and we will be working on it once we move the service to a production domain.
Picture this!
Functionally, WCQS is very similar to WDQS. The user interface is almost identical. Examples are a great place to start, and community members have already provided a lot of fun ways to explore the SDC + Wikidata datasets. Starting from the everlasting first Wikidata example, now transferring to SDC – depictions of the late Douglas Adams, in ImageGrid:
#defaultView:ImageGrid
SELECT ?file ?image WHERE {
?file wdt:P180 wd:Q42 .
?file schema:contentUrl ?url .
bind(iri(concat("http://commons.wikimedia.org/wiki/Special:FilePath/", wikibase:decodeUri(substr(str(?url),53)))) AS ?image)
}Results of this query look like this:
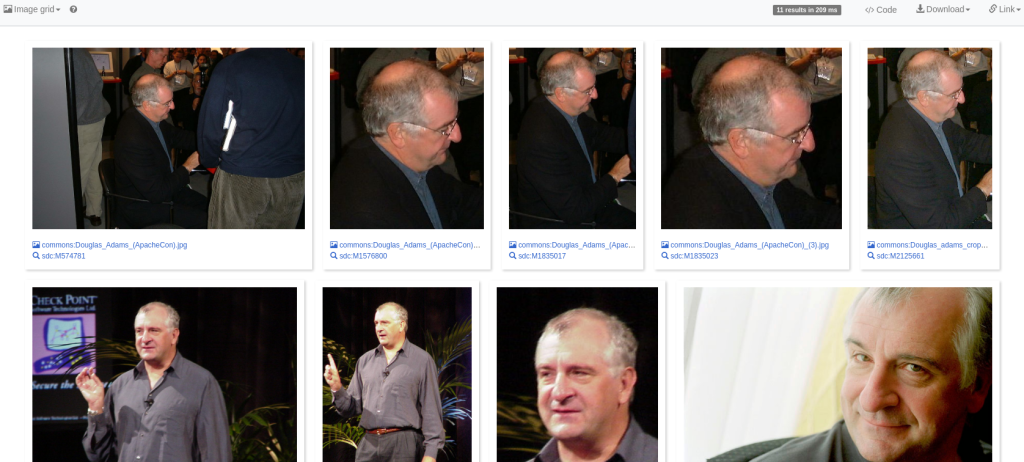
This query only leverages the SDC dataset. Let’s add Wikidata into the mix to demonstrate federation.
Here’s one example showing images published in the German magazine Die Gartenlaube, made possible thanks to the Wikidata federation.
#Illustration published in German magazine 'Die Gartenlaube' using Wikidata federation
#defaultView:ImageGrid{"hide":["?img2"]}
select ?articleLabel ?articleDesc ?article ?img2 ?imgDesc
with {
select * {
# SELECT all articles published in German magazine 'Die Gartenlaube'
service <https://query.wikidata.org/sparql> {
?article wdt:P1433 wd:Q655617;
rdfs:label ?articleLabel;
schema:description ?articleDesc.
FILTER (LANG(?articleLabel) = "en")
FILTER (LANG(?articleDesc) = "en")
}
}
} as %items
where {
include %items .
#select images published in any article.
?file wdt:P1433 ?article;
schema:contentUrl ?img ;
optional {?file rdfs:label ?imgDesc. FILTER(LANG(?desc) = "de") } .
# workaround to show the images in an image grid
BIND(IRI(concat("http://commons.wikimedia.org/wiki/Special:FilePath/", wikibase:decodeUri(substr(str(?img),53)))) AS ?img2)
}This query uses federation to find articles published in (P1433) the German magazine Die Gartenlaube, together with some information about those articles; then, having retrieved that set, it finds Commons files with SDC statements that indicate the images were published in (P1433) those articles. The first few items found:

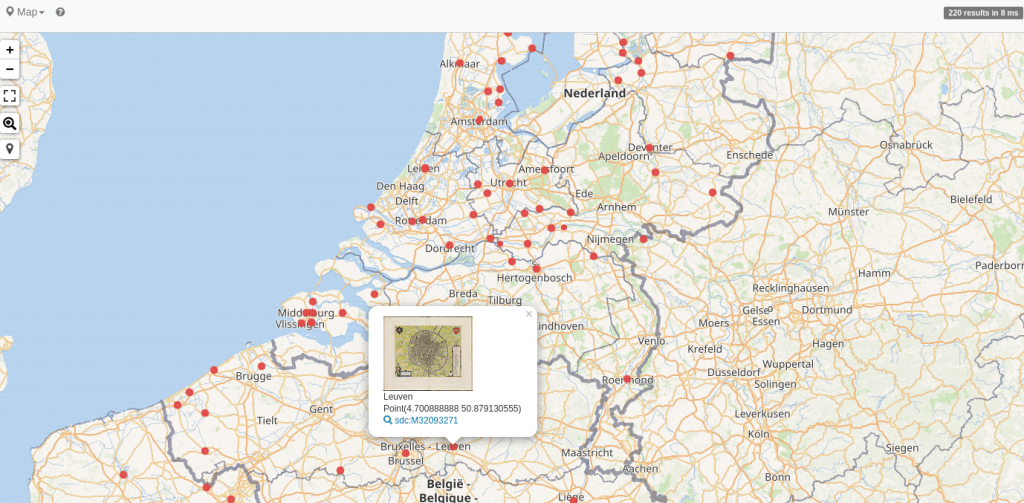
How about we use coordinates from Wikidata to not only show some images, but also place them on a map, courtesy of Map view? An example showing images found in the medieval “Atlas De Wit” does just that:
#Map of images found in the medieval Atlas De Wit
#defaultView:Map
SELECT ?file ?image ?depictionLabel ?coord WHERE {
?file wdt:P6243 wd:Q2520345 .
?file wdt:P180 ?depiction .
?file schema:contentUrl ?url .
SERVICE <https://query.wikidata.org/sparql> {
?depiction wdt:P625 ?coord.
SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en" .
?depiction rdfs:label ?depictionLabel .
}
}
bind(iri(concat("http://commons.wikimedia.org/wiki/Special:FilePath/", replace(substr(str(?url),53),"_","%20"))) AS ?image)
}
The road to production
As mentioned before, WCQS is now in beta. Our experience with maintaining WDQS showed us just how difficult it is to keep a SPARQL endpoint running. We want to make sure not to recreate the same issues WDQS had and is still having – mostly focused around performance – when transitioning WCQS out of beta. We will also address other issues, like the lack of real-time updates.
We do plan to move to production, but don’t have a timeline yet. We want to emphasize that while we do expect a SPARQL endpoint to be part of a medium- to long-term SDC querying solution, it will only be part of that solution. Even once the service is production-ready, it will still have limitations in terms of timeouts, expensive queries, and federation. Some use cases will need to be migrated, over time, to better solutions.
Evolution, now in Technicolor
Wikimedia Commons Query Service is a community-driven effort and all of you can participate in its evolution. Create a ticket with the tag wikidata-query-service or reach out directly on IRC (freenode:#wikimedia-discovery) to let us know of any issues or ideas you have.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation