Summary
In the second month of the humaniki project, we finished our user-research, finalizing which features we’ll develop; as well as continued merging the WHGI and Denelezh codebases.
To finish our user research we synthesized interview findings in a process that identifies the highest-value future development efforts, like comparison, evolution, and completeness views. In software development, we started coding our data-processing layer, the HTTP API, and three interactive visualizations for gender by date of birth, project language, and citizenship.
User Research
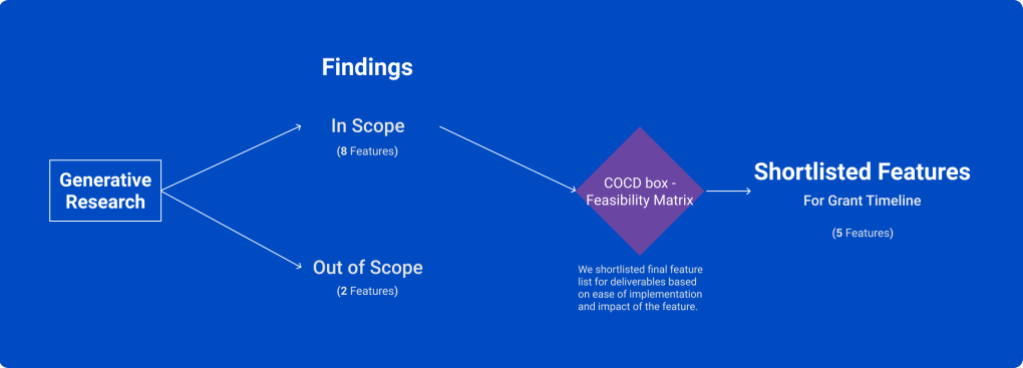
We conducted generative research with community members to identify needs in the diversity space and integration opportunities (Figure 1). We released a research report (see slideshare below) that entails our research background, methodology, and findings that will inform humaniki’s future development features.
Personas
Personas are archetypes created to represent a user type of tool/website. We identified 6 personas for humaniki – academic researchers, community developers, diversity-focused editors who are inclusionist (English and non-English speakers), community leaders, and activists (Figure 2). You can learn more about individual personas in our comprehensive research report.

Research Insights
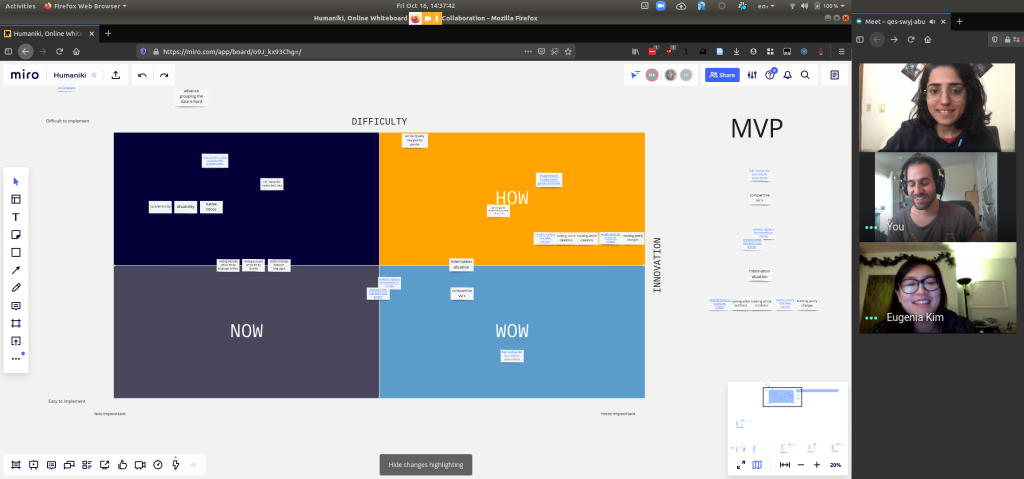
We grouped 8 in-scope elicited features from interviews into 4 main categories/themes based on their functional similarities. We further converged our feature list using a feasibility matrix (Figure 3) based on ease of implementation and impact of the feature (* represents shortlisted features). We shortlisted 5 features for MVP based on the grant timeline. We provide a brief list below but you can view our research report to learn fully about the identified use cases.
(from top to bottom: Sejal Khatri, Maximilian Klein, Eugenia Kim)
Theme 1: Improving the usability of the data we already collect by making it more shareable, more searchable, and more re-usable.
- Publication ready presentation for creating awareness.*
- Customizable and comparative visualizations to enable data exploration.*
- Enabling third-party applications via data API to help accelerate the efforts of community members and spur research in the diversity domain.
Theme 2: Expanding the dimensions of the existing data, including different attributes of humans, the snapshot of the data when collected, and the interface language.
- Gender gap evolution to track diversity trends * – Enabling tracking of content diversity over time.
- Maximizing currently collected gender gap data and providing statistics about other categories interlinkings between gendered content.
- Internationalization – Make tools also available in non-English language interfaces.*
Theme 3: Providing actionable insights by highlighting editing opportunities on Wikidata and Wikimedia projects.
- Customized List Making – Providing advanced search features not only to view diversity trends but also to extract a list of relevant articles for improvement.
- Data Completeness to improve structured data source * – Highlight information gaps on our data source, Wikidata, to create high impact improvement opportunities for knowledge gaps on Wikidata.
Theme 4: Retain highly used features and statistics already in use by the community. *
While our research goal was to elicitate new features requirements based on community needs in the diversity space, we also identified the some WHGI and Denelezh features being highly used by core community representatives. We will retain the functionality and polish the highly used features to avoid disrupting the experience for existing users.
Technical Updates
We continued the task of retaining (and maintaining) the current features by developing a new “backend” API layer, and a fully interactive web-app. Our progress this month is that the Python-Flask backend successfully serves up data for the Date of Birth View, Language View, and the Country View. The frontend development process has implemented the graph and table views. We continue to work toward full user interactivity and filtering.
You can track our latest progress here:
- https://github.com/notconfusing/humaniki-schema
- https://github.com/notconfusing/humaniki-backend
- https://github.com/theeugeniakim/humaniki
Interested in participating?
We are still accepting survey responses for future research purposes and looking for diversity-focused editors interested in providing inputs for the project. Please sign up here if interested – link.

Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation