
The interconnection between Wikipedia and Wikidata is now larger than ever.
The Wikipedia Citations dataset currently includes around 30M citations from Wikipedia pages to a variety of sources – of which 4M are to scientific publication. The increase of the connection with external data services and the provision of structured data to one of the key elements of Wikipedia articles has two significant benefits: first of all, a better discoverability of relevant encyclopedic articles related to scholarly studies; furthermore, the enacting of Wikipedia as a social authority and policy hub which would enable policymakers to assess the importance of an article, person, research group and institution by looking at how many Wikipedia articles cite them.
These are the motivations behind the “Wikipedia Citations in Wikidata” project, supported by a grant from the WikiCite Initiative. From January 2021 until the end of April, the team of Silvio Peroni (Director of OpenCitations), Giovanni Colavizza, Marilena Daquino, Gabriele Pisciotta and Simone Persiani from the University of Bologna (Department of Classical Philology and Italian Studies) has been working in developing a codebase to enrich Wikidata with citations to scholarly publications that are currently referenced in English Wikipedia. This codebase consists of four software modules in Python and integrates new components (a classifier to distinguish citations by cited source and a look-up module to equip citations with identifiers from Crossref or other APIs). In so doing, Wikipedia Citations extends upon prior work which only focused on citations already equipped with identifiers.
In the first two steps of the workflow (extractor and converter) the mapping between the various ways Wikipedia citations are represented in Wikipedia articles and the OpenCitations Data Model (OCDM) has been implemented and then enriched with a component responsible to find new identifiers to the entities in a dataset compliant with OCDM (enricher), while in the pusher step the mapping between the OCDM and Wikidata has been enabled, and the code has been finally released in GitHub.
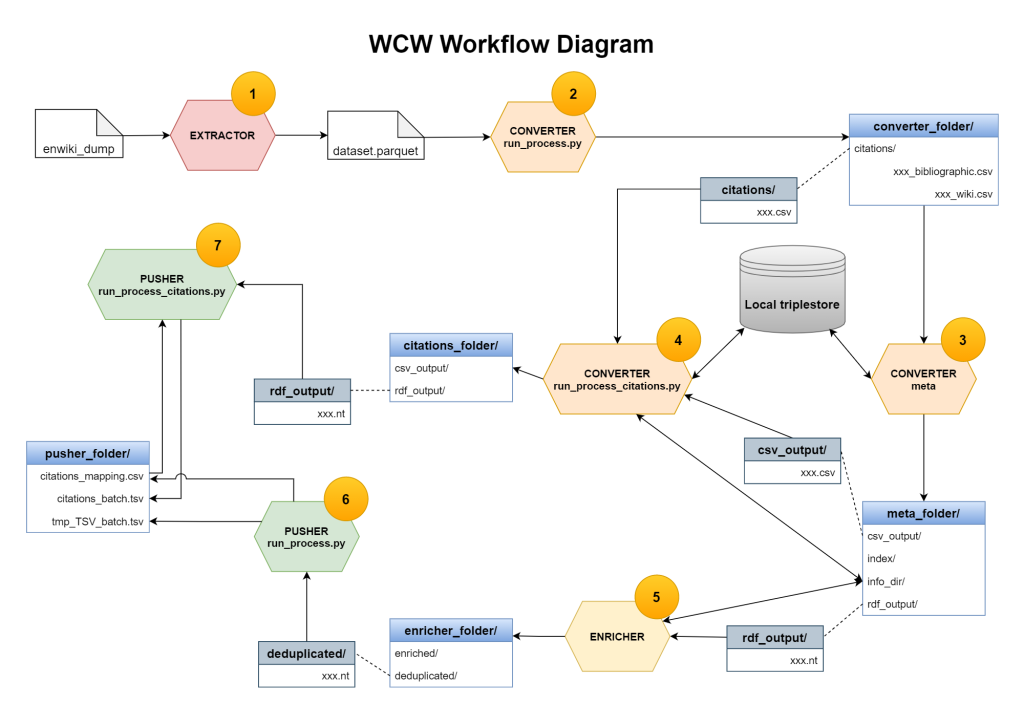
The extensive documentation that has accompanied the release of the codebase is crucial for one of the principal aims of the project, I.e., the adoption and reuse of the codebase by the community in other relevant Wikimedia projects, while the engagement of various communities (Wikidata, libraries, scholars…) is favored on one side by offering an increased number of citations data included in Wikidata, on the other side by blogging and sharing the updates on Twitter and public mailing lists
This project, whose ambitious purpose is to make Wikipedia contents better discoverable and enrich Wikidata with a ready-to-use corpus for further analysis or for developing new services, is opened to future perspectives. The intention is to use the software to create a dataset of Wikipedia English citations to understand, in particular, how many new entities (i.e., citing Wikipedia pages, cited articles and venues, authors) should be added to Wikidata in order to upload all the set of extracted citations, with the result of adding a massive amount of new bibliographic-related entities to the dataset.
The first steps have been taken, now we aim to extend the engagement of the community involved, especially those scholars that leverage Wikidata in existing services, and to interact with the scholars, libraries and institutions interested in a new approach to research, focused on people (from individuals to research groups) and their intellectual relevance.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation