The Abstract Wikipedia team has taken further steps toward representing abstract content in natural languages!
When Denny introduced the proposal for Abstract Wikipedia here on Diff, he noted the need for “functions that can translate the content of Abstract Wikipedia into the natural language text of every Wikipedia.” Those “functions” will eventually comprise a community-driven natural language generation pipeline. Research and prototyping for that NLG pipeline have now begun. In this post, we will outline how the architecture of the NLG templating system (part of the NLG pipeline) fits in with other components. We’ll also highlight open questions in the hopes of encouraging discussion and further contribution by the community.
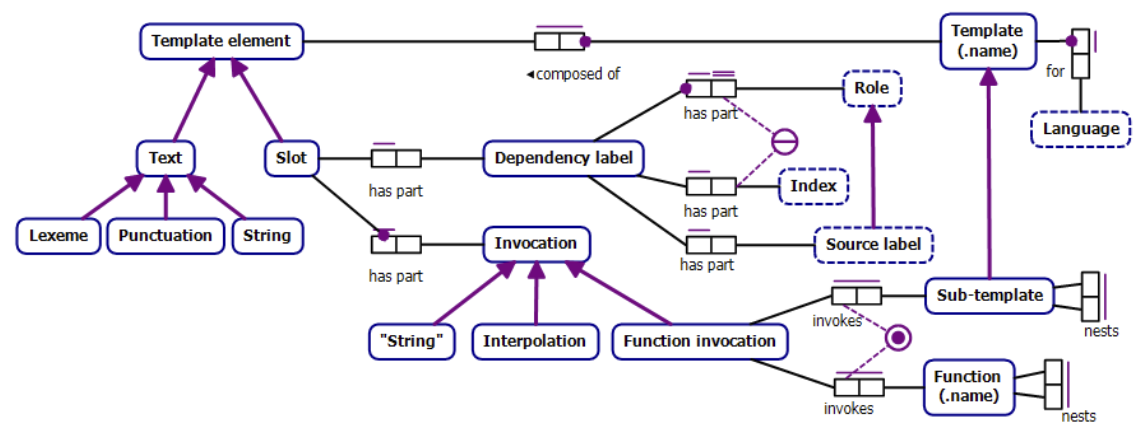
As the AW team discussed a few weeks ago, the planned NLG realizer, also called Renderer, and a component of the NLG system, will use a template language to help write templates and then it will transform templates into natural language text. The template language will provide a high-level, readable, declarative syntax to steer text generation from the abstract content (captured with the constructors). Then, the template language parser will produce a series of function compositions, whose details are further described in Google.org Fellow Ariel Gutman and Professor Maria Keet’s template language specification. It’s important for us to begin creating some standards for these functions now in order to limit complexity and ensure interoperability, so that abstract content can indeed benefit all languages and so that the community can write Constructors and Renderers on Wikifunctions with relative ease. Some of the complexities regarding doing NLG in agglutinating African languages have been addressed by Maria Keet in a TechTalk she gave to Google fellows in a meeting they held in Zurich in August.
To have a better idea of how the NLG realizer’s implementation may look, Ariel Gutman has started creating a Scribunto prototype, which will inform the Wikifunctions implementation. Mahir Moshed has also created the Ninai and Udiron libraries in Python to prototype the realizer. We will share more about the prototype in a future Diff post. At the same time, Google.org Fellow Sandy Woodruff has started reflecting about a dedicated UI for the NLG system. You can learn about some of her ideas in a brainstorming session held at the aforementioned meeting.
One open question concerns the Constructors themselves. A Constructor represents a piece of abstract content. Let’s adapt an example from the template language specification:
Age(
entity: Malala Yousafzai (Q32732)
age_in_years: 25
)
This is a Constructor that represents a fact true at the time of writing, namely the age of Malala Yousafzai, which would be rendered in English as “Malala Yousafzai is 25 years old.” Note that, in reality, “age_in_years” would itself likely be defined by a function call that calculates age based on birth date and the present date, but this detail is omitted here for clarity.
Many of our open questions concern how representative this example Constructor is. This example represents a single proposition and can be realized as a sentence in most (maybe all?) natural languages, but will that be true of all Constructors? What if some Constructors embed multiple propositions? Is it possible for a Constructor to correspond to an incomplete proposition?
Another set of questions concerns how general the relationship between a Constructor and its participant entities should be. We might imagine a Constructor for the sentence, “Bi Sheng invented movable type in 1040 AD.” In order to make Constructors reusable across languages and for multiple propositions, we would want to enshrine more general scenes or frames like “Age” above or, in this case, “Invent.” What, if any, linguistic formalization should be adopted for this purpose? FrameNet is one possibility, but might another work better, or does Abstract Wikipedia demand an ad hoc solution? How do we handle information which belongs in a sentence but isn’t intrinsically part of a proposition, e.g. “in 1040 AD” from the given example, which isn’t a “core” part of the notion of inventing something the way that the inventor and invention are? Kutz Arrieta from Google has begun thinking about these questions.
Once the Constructors have done their job, the Renderers’ work begins. The working NLG proposal presumes that the lexical forms in Wikidata will be marked with grammatical features (e.g., number for nouns and verbs, gender or class for substantives, aspect and tense and mood for verbs, …). Mahir Morshed and the rest of the NLG contributors have begun work on standardizing these representations in Wikidata’s lexicographical content, but our NLG system can’t assume the data will always be present or complete. Therefore, our questions here concern how to address missing lexical data. When the system generates a sentence, can it provide multiple possibilities for words it’s uncertain about? Should it allow the user to add new terms at that time? If so, how would it guide them to contribute to Wikidata from another project’s context?
These are big questions, but hopefully the challenges they present look exciting, rather than intimidating. As always, we welcome your contributions. We hope that the breadth of experience and sheer number of languages present within the community will help us find the most equitable solutions possible.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation