Tim Sherratt is a historian, hacker, and Associate Professor of Digital Heritage at University of Canberra. He runs the GLAM Workbench, a collection of guides to help you explore and use data from galleries, libraries, archives, and museums, and earlier this year received a grant from Wikimedia Australia to explore and create integration of Australian government agency data with Wikidata. This is part one of two articles where he discusses his recent work.
Over the last few months, with the support of Wikimedia Australia, I’ve been working on two related projects. The first aims to add information about federal government agencies from the National Archives of Australia to Wikidata. The second involves the addition of a new Wikidata section to the GLAM Workbench. This will provide examples of using and visualising the agencies data and, more generally, help introduce Australian humanities researchers to some of the possibilities of Wikidata.
One of the most exciting features of Wikidata, is its ability to connect disparate data sources. By bringing together links for the same entity in different systems, Wikidata exposes a network of relationships and contexts – only visible otherwise as a series of slices in individual data silos. Of course this isn’t new. I’m old enough to remember adding data to Freebase, and back in 2010 I got very excited about the National Library’s People Australia service (now the People & Organisations category in Trove). But with a large community of contributors, and an open, evolving data model, Wikidata overcomes many of the limitations of earlier systems and provides a platform where anyone can start connecting things up.
The National Archives of Australia (NAA) captures information about the activities of the federal government – not just the records it creates, but also the histories and functions of the agencies that implement its policies. Like Wikidata, the NAA aggregates information about individual agencies and exposes it via a permanent identifier. For example, the Attorney-General’s Department has the identifier CA 5. If you follow the link you’ll see lists of related agencies, functions, people, and records series. These rich relationships are documented using the Commonwealth Record Series System – a data model developed in the 1960s that was quite innovative in thinking of archival documentation in terms of entities and relationships.
Unfortunately, RecordSearch, the online interface to the NAA’s collection data, is isolated from other systems, and limited in its ability to query across related entities. Even sharing links is difficult – the use of browser sessions means that saved urls stop working (though I’ve created a tool to help with this). How can we make better use of this rich and important data to support new ways of seeing and understanding the workings of the Australian government over time?
As a first step, I’ve started adding NAA identifiers and basic agency information to Wikidata. As of today, there are 1,482 Australian government agencies with NAA identifiers in Wikidata. You can view a list by running this query using the Wikidata Query Service. As well as the identifiers, I’ve been adding start and end dates from RecordSearch, and making sure the Wikidata items are instances of either ‘Australian government body’ or ‘department of the Australian government’ (for Departments of State). This means you can easily construct a query that shows all government departments from 1901 with their life dates. The agencies added so far include all departments and most of those with the status of ‘Head Office’ in RecordSearch. This label is a bit misleading it includes bodies such as Royal Commissions and courts, as well as a host of others boards, bureaus, councils, and committees.
Data wrangling
Getting data out of RecordSearch is not straightforward, but over the years I’ve developed a set of tools to help. The RecordSearch Data Scraper is a Python package that turns RecordSearch queries into machine-readable data. You can try it out in the RecordSearch section of the GLAM Workbench. There’s no simple way of searching for all agencies, so I looped through a range of numbers from 1 to 10000, and searched for agencies matching ‘CA 1’, ‘CA 2’, ‘CA 3’ etc. I ended up with a dataset containing the details of 8,558 agencies. To process the data I used a variety of tools – Python and Jupyter notebooks to filter and reorganise the NAA data, OpenRefine to look for matches with existing Wikidata entities and build an upload schema, and QuickStatements to modify or create Wikidata items.
Before adding the NAA identifiers to Wikidata, I needed to create a property to attach them to. This involved developing a property proposal for an NAA Entity ID and seeking feedback from other Wikidata users. Once there was agreement that the proposal was worthwhile, it was created. Wikidata properties are themselves entities within Wikidata and include definitions, constraints, and examples.
I used existing properties like `inception’ and ‘dissolved, abolished or demolished date’ for the start and end dates, but finding the best way of describing relationships between agencies was a bit more challenging. When a government decides to shake up the names and responsibilities of government departments, the lines of succession are rarely clear cut. A department’s functions might be split between two new departments, or merged back into an existing department. There are properties for ‘replaces’ and ‘replaced by’, but I couldn’t find a good way of expressing the partial transfer of responsibilities. Property values can be qualified, so it might be possible to indicate where ‘replaced by’ applies to specific government functions. However, while RecordSearch documents functions and applies them to agencies, their use in describing relationships between agencies is inconsistent. Another complication is that both ‘replaces’ and ‘replaced by’ expect there to be inverse relationships – if Department A replaces Department B, then Department B is replaced by Department A. But this doesn’t quite work if Department B hands some of its functions to Department A, but continues to exist – has it actually been replaced? Ah, the fun of data modelling!
To avoid over-complicating things I decided to focus on instances where the transfer of responsibilities involved the end of one department and the start of another. If responsibilities were split or merged, I added multiple ‘replaced’ or ‘replaced by’ values, with the thought that I might improve these further in the future by adding qualifiers. This means that some connections will be missing, but at least provides a clear set of relationships to build on.
Once I’d added each department’s predecessors and successors, I started to explore ways of visualising the connections. While the Wikidata Query Service includes a number of useful visualisation tools, I wanted a bit more control over the output, and to build some examples I could extend further within the GLAM Workbench.
My first attempts at creating a network graph of agencies showed a number of isolated nodes, with few or no connections. This seemed odd. Looking back at RecordSearch I realised there were some problems with the data. For example, the Department of Aboriginal Affairs is described in RecordSearch as a ‘Head Office’ rather than a ‘Department of State’. As a result, I’d overlooked it in my first upload of departments. As it was missing from the graph, departments connected to it became isolated from the broader network. There are some other issues with the RecordSearch data that I’m still working through. Visualisation is always a great way of finding problems with your data!
The completed network graph shows how the number and arrangement of departments has changed over time. It’s structured hierarchically with the earliest agencies at the top, and is grouped by decade. The size of a node indicates how long an agency was in existence, while the colour shows the decade in which it was created.
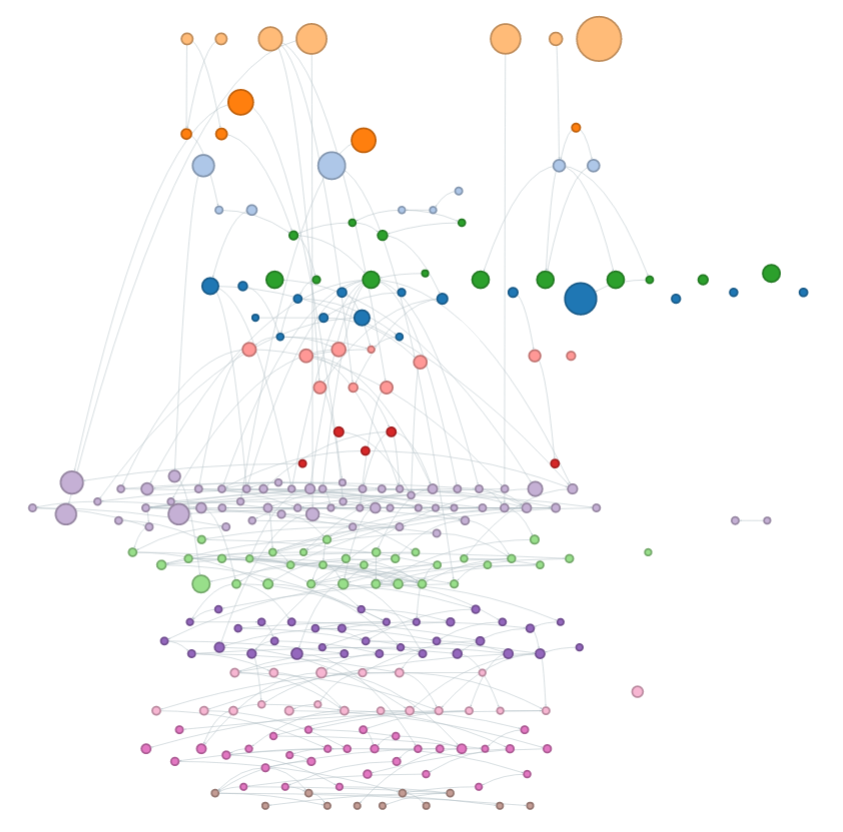
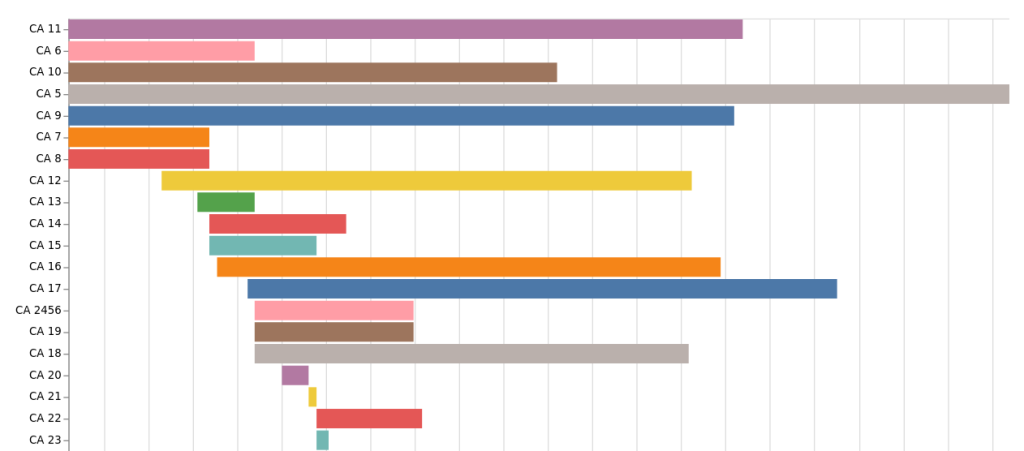
Little change is evident in the early decades, though the impact of World War II and its aftermath can be clearly seen. The pace of change quickens dramatically in the 1970s. Since then, agencies have changed names and functions frequently. You can explore an interactive version of this visualisation in the GLAM Workbench. You can also play around with the code that built in this Jupyter notebook. I’ve also created a little tool to build a network graph around a single agency that you can run live using Binder – just select an agency from the dropdown list. For an overview of departments and their lifespans, you can create a Gannt-style chart using this notebook.
What’s next?
While the agencies data is fascinating in itself, what interests me most about this sort of work is how we can extend, enrich, and enhance the interfaces provided by GLAM organisations. With the NAA identifiers in Wikidata, and properties and relationships aligned, we can explore the NAA’s holdings in new ways. We can construct complex queries that traverse relationships and filter outputs that are impossible within RecordSearch itself. We can start to ask different types of questions.
Working with the NAA data has got me thinking about other ways of using Wikidata in research around GLAM collections. I’ve added a Wikidata section to the GLAM Workbench and will be adding a variety of tools, notebooks, and examples shortly, but I’ll save those details for a follow-up post!
You can keep up to date with Tim Sherratt and his work on his website and Twitter. Part two of this article will be posted later in November.
Originally posted by Tim Sherratt to Wikimedia Australia on 31 October 2022.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation