Hi! I’m Trey, and I’m a computational linguist* on the Wikimedia Search Platform team. I like to say that my role on the Search team is to improve language processing for search—especially for languages other than English. It’s not the only thing I do, but it’s my favorite, for sure. I want to tell you about the “language analyzer unpacking” project that I’ve been working on over the last couple of years, to directly improve search in a few dozen languages, and as part of a larger effort to improve and “harmonize” search across all the languages we support. Along the way, I’ve discovered some fun facts about various languages, and uncovered some bothersome bugs in their analyzers. Come and join me for an overview of the project, and take the opportunity to appreciate language in its near infinite variety!
Prelude—Language Analysis
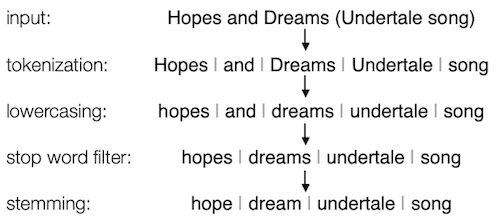
Language analysis is a series of steps to prepare text—like Wikipedia articles—to be indexed by a search engine. It can include general text processing or language-specific processing, and either can be fairly simple or quite complex. Queries from searchers are similarly processed, so that text from a query can be compared to the text in the search index.
The on-wiki search for Wikipedia, Wiktionary,‡ and the other language-specific projects is provided by CirrusSearch, which is a MediaWiki extension currently built on top of the Elasticsearch search engine, which is in turn built on the Apache Lucene search library.
Lucene provides language analysis components in about three dozen languages.§ Most language analyzers have a few standard components:‖
- Tokenizing—which is usually breaking text into words, more or less
- Lowercasing words—so searching for any of hope, HOPE, and Hope will find the others
- Stop word filtering—so that words like the, of, is, and, and others are ignored or discounted
- Stemming—which approximates the root forms of words, so that searching for any of hope, hopes, hoped, and hoping will find the others
Many language analyzers have additional specialized forms of normalization, which typically consists of converting certain characters into related characters that are more standard or easier to work with; lowercasing is a kind of normalization. Several languages have elision processing, so that in French, for example, l'élision will match élision. Turkish has another special kind of apostrophe handling, which we’ll talk about later. If you want to know more—a lot more—about tokenization, normalization, stemming, and stop words, see my series of blog posts on The Anatomy of Search.
For ease of implementation and configuration, the set of default analyzer components for each language is bundled together by Elasticsearch as a preconfigured analyzer. Rather than having to configure everything you need, you can get pretty good language analysis for Armenian, Basque, Czech, Dutch, Estonian, Finnish, Greek, Hungarian, Indonesian, etc., by just specifying the language analyzer you want by name. Easy-peasy!
Normalization—I See You, Unicode
However, reality is not quite that easy.¶ Big wiki projects have text in a lot of different languages—which use several dozen writing systems#—as well as technical symbols, uncommon character variants, and all kinds of “interesting” formatting and typography. As much as possible, we want that kind of thing to be transparent to searchers.
For example, if someone searches for—
- … chu Quoc ngu, we want them to match chữ Quốc ngữ—especially on wikis where you wouldn’t expect searchers to be using Vietnamese keyboards
- … βαρβιτιστησ—because they can’t type Greek accents, forgot about final σ/ς in Greek, and have no idea about the French habit of using ϐ for β in the middle of a word—we want them to match βάρϐιτιστής
- … Hawai'i, we want them to match the more correct Hawaiʻi, along with the variants Hawai’i, Hawai‘i, Hawaiʼi, and HawaiʹiΔ
- … Wikipedia, using full-width characters, we want them to match Wikipedia, and similarly, if they search for halfwidth ウィキペディア we want them to match ウィキペディア
- … pretty much anything, we want them to match words with unexpected invisible characters, such as left-to-right and right-to-left bidirectional marks, soft hyphens, variation selectors, and various “joiner” and “non-joiner” characters
Fortunately, the open-source project International Components for Unicode (ICU), provides libraries that support these kinds of Unicode normalizations, and they have been wrapped into Elasticsearch plugins. Two of the most generally useful for us are ICU Normalization and ICU Folding.
ICU Normalization does many useful things:
- properly lowercasing some less common scripts and rare characters (see examples below)
- converting sometimes visually indistinguishable characters (your mileage may vary depending on your fonts), like µ → μ, ﯼ → ی, ㄱ → ᄀ, and ̀ → ̀
- converting numerous characters to more “standard” forms, such as ſ → s, ϐ → β, ς → σ, ﹖ → ?, and ︵ → (
- deleting the invisible characters mentioned above

[N.B.: Since Cherokee lowercase forms are rarely used, they are normalized to uppercase.]
The full list doesn’t seem to be documented anywhere, so back in 2020 I worked it out by brute force. I found that ICU Normalization isn’t perfect, but it does a lot of good!
ICU Folding, in contrast, is much more aggressive, and seems to want to reduce every character to its most basic form—diacritics be damned! For example, it will convert any of à, á, â, ã, ā, ă, ȧ, ä, ả, å, ǎ, ȁ, ȃ, ą, ạ, ḁ, ẚ, ầ, ấ, ẫ, ẩ, ằ, ắ, ẵ, ẳ, ǡ, ǟ, ǻ, ậ, ặ, ⱥ, ɑ, ɐ, or ɒ to simple a. As an English speaker, that’s brilliant, because I can barely remember how to spell Biàncáitiān or epäjärjestelmällistyttämättömyydellänsäkäänköhänkään, much less how to type all those accented characters. However, on a Finnish-language wiki, we want to be able to distinguish a/ä & o/ö—and a/å, too. Swedish agrees with that list, while Danish and Norwegian each have their own list of letters not to mess with. Basque, Galician, and Spanish just want n/ñ left unmerged. Thai and Japanese have lists, too—as do many—maybe even most—other languages. So, we need to rein in ICU Folding in a language-specific way for many languages, but it’s worth it because it makes searching for foreign text easier—where foreign depends on the context of the wiki you are on, of course.
Beyond improvements that the ICU components can provide, we’ve configured other Elasticsearch components—or in some instances written our own—to help take care of some other “interesting” circumstances we’ve run across over the years.
So, if someone searches for—
- … ac bo wri mo, they should match AcBoWriMo
- … Wikimedia Phabricator, they should match phabricator.wikimedia.org
- … screaming snake case, they should match SCREAMING_SNAKE_CASE
- … chocolate, they should match chocоlate—where that sneaky bold letter in the middle of the word is actually a Cyrillic character; such characters that look almost identical are called homoglyphs, and they are my personal nemesis when it comes to searching!
Monolithic Technical Debt—Unpacking
Unfortunately, the default bundled analyzer configurations provided by Elasticsearch cannot be customized with ICU components or components we’ve configured or written ourselves. They each come as just one piece; hence the label monolithic. Fortunately, Elasticsearch spells out the components of each monolithic analyzer and we can reconstitute them as “custom” analyzers, which can then be further modified and upgraded to deal with issues like those above.
In theory, this is great, and allows us tons of flexibility! In practice, it has been a bit of a speed bump when it comes to making improvements or fixing bugs, because the first step to making an otherwise quick, simple fix◊ has often been “unpacking” a monolithic analyzer.
When unpacking, we first verify that we get the exact same performance out of the unpacked analyzer as the monolithic analyzer, which is pretty straightforward. However, stopping there would require disabling a small suite of default upgrades we have for non-monolithic analyzers, like using ICU Normalization instead of simple lowercasing, enabling homoglyph handling, and a couple of fixes for little bugs we’ve found in various analysis components. Of course, we want to turn on all those upgrades, but they do require a bit of testing. And since we’re here, wouldn’t it be great to enable (appropriately customized) ICU Folding? Of course it would!

After thinking about our ad hoc unpacking of a few analyzers, we realized that, for us, monolithic analyzers constitute technical debt—they make it hard to make specific improvements for certain languages, and they prevent us from making general improvements everywhere at once.↓
So now, hopefully, you have a better idea what “language analyzer unpacking” means! The immediate goal has been to unpack all the existing language analyzers, enable our default upgrades, and enable and customize ICU Folding for each, and that’s what I’ve been working on for big swathes of the last two years.
What a long strange trip it’s been.
Testing, Testing—Is This Thing On?
Over years of working with languages—testing analyzer changes, doing general analysis of analyzer behavior, and analyzing largish Wikipedia and Wiktionary samples—and trying to figure out how best to highlight potential problems,☞ I’ve developed some scripts that I redundantly recursively repetitively reduplicatively refer to as my “analysis analysis” tools.
Among the things I’ve learned to do and to look out for:
- Groups of words that have the same stem, but don’t have any initial or final letters in common. Sometimes it’s actually pretty cool: the English stemmer stems Dutch and Netherlands the same, and Filipino and Philippines the same. Other times it’s a sign something has gone weirdly wrong.
- Really large groups of words that stem together. Sometimes it’s a common word with many forms. Sometimes it’s two or more words that have overlapping forms. Other times it’s a sign something has gone weirdly wrong.
- Really long words. Sometimes it’s just a somewhat excessive German compound, or a very large number, or a URL, or a sentence in a language that doesn’t use spaces, like Thai. Other times it’s a sign something has gone weirdly wrong.
- Highlighting invisible characters. If a word has a soft hyphen in it or a left-to-right mark on it, no one is ever going to type it that way, so it is essentially unfindable!
- Color-coding mixed-script tokens so it’s easier to see what’s going on. If a word like chocоlate has an undetectable Cyrillic letter in it, no one is ever going to type it that way, so it is essentially unfindable!

I guess it’s clear that I’m a bit obsessed with things that are essentially unfindable and other instances where something has gone weirdly wrong!
Of course, it’s also important to test any changes made to an analysis chain. My analysis analysis tools highlight where words that used to be distinct are now analyzed as the same, or vice versa, along with tokens that used to exist but no longer do, or vice versa.
Another aspect of testing and analysis that I took up for this project is reviewing changes in results for a sample of queries, after updates have been made. There is enough evidence from looking at the changes that occur in the Wikipedia and Wiktionary samples I test on before deployment to generally be sure that any analyzer changes are correct. This extra step of looking at queries after deployment helps to assess the impact of the changes.
Note that, in general, paying down technical debt can result in no visible changes to software behavior—cleaner code might run a little faster and it’s definitely easier to work with, which pays dividends in future development. However, in this case, ICU Normalization and ICU Folding often make a small but clear improvement** to the number of queries that got zero results, and have a similar impact on the number of results returned in general. As an example, without ICU Folding, searching for Biancaitian will not find Biàncáitiān. Depending on many factors, there might be zero, a few, or many instances on a wiki of a word without its preferred diacritics, but in general being able to search without foreign diacritics (and without having to figure out how to type them) increases the number of useful results.
This extra query-testing step has slowed down the overall unpacking development process a little, but it’s been nice to get a sense of the impact the upgrades are making along the way.
You Say Anecdota, I Say Anecdata
As mentioned above, and below—speaking of below, you are reading the footnotes, right? Those are some quality footnotes! Anyway, as mentioned above and below, things are often not quite as easy nor quite as peasy as one would hope.
During my testing and analysis, I’ve discovered some fun facts about various languages, and uncovered some bothersome bugs in their analyzers. Let’s take the opportunity to appreciate language in its near infinite variety!
❦ Turkish—Non-Native Apostrophe Angst
Apostrophes are used in Turkish to separate proper names from suffixes attached to them—e.g., Türkiye'den (“from Turkey”)—presumably because without the apostrophe the boundary between an unfamiliar name and the suffixes could be ambiguous. English does something similar with a's, i's, and u's—which are the plurals of a, i, and u—to distinguish them from the words as, is, and us.
Elasticsearch/Lucene has apostrophe handling that is specific to Turkish, and it removes the first apostrophe it finds in a word, plus everything after the apostrophe. That’s reasonable for native Turkish text, but it’s disastrous for non-Turkish words and names, like D'Artagnan, d'Ivoire, and d'Urbervilles—which are all reduced to d—or O'Connell, O'Keefe, and O'Sullivan—which are all reduced to o, which is a stop word!

Since there are a lot of references and online material in French, plenty of French shows up in Turkish Wikipedia (and many Wikipedias), and the apostrophe handling does baaaad things to much of it. Even worse, the apostrophe handling doesn’t consider when it’s looking at non-Latin text, so some very-not-Turkish words like επ'ευκαιρία, прем'єр, and ג'אלה are also subject to apostrophe-chopping.
The Turkish apostrophe is also used for single letters, whether talking about the letter or something labelled by the letter (e.g., “group B”), so you see forms like B'dekilere (“to those in B”). However, in my data, d' is overwhelmingly an indicator that something is in French. These two trends clash in my favorite Turkish apostrophe example, d'nin. Both d' and 'nin mean “of”—so it’s either French for “of nin” or Turkish for “of d.” In the context of a Turkish wiki, assuming that it’s “of d” seems more likely to be the safe bet.
To process non-Turkish words with apostrophes better—and Turkish words with non-apostrophes, similar to the Hawai'i examples above—I took a detour from unpacking and developed a new, better apostrophe handler, somewhat smugly named “better_apostrophe”.
All of the cases, and exceptions, and exceptions to exceptions I had to consider are laid out in detail in the better_apostrophe ReadMe.
❦ Romanian—Cedillas & Commas, Confused & Conflated
While reading up on the Romanian alphabet—in order to learn which Romanian letters needed to be exempt from ICU Folding—I learned that there is a common confusion between ş and ţ (with cedilla, not officially Romanian letters) and ș and ț (with comma, the correct Romanian letters). There are plenty of examples of both on Romanian Wikipedia, though the correct comma forms are generally much more common.
As noted in the Wikipedia article linked above, there was a major lack of support for the proper Romanian characters up until the mid-to-late 2000s. While working to merge ş/ș and ţ/ț for search purposes, I realized that the Romanian stop word list and the Romanian stemmer used only the older, incorrect cedilla forms of words! Those components were made in the bad old days†† (typographically speaking) and hadn’t been updated since.
When I added the comma forms to the stop word list, it excluded 1.4% of words from my Wiktionary sample, and 3.4% of words from my Wikipedia sample—in both cases, the vast majority of individual words were și, (meaning “and”). Properly making și a stop word will improve both the number of results returned (it is no longer required to get a match) and the ranking of those results (it’s discounted when it does match). As an example, when searching for Bosnia și Herțegovina, matches with Bosnia and Herțegovina will (and should) be weighted much more heavily than matches with și.
There are also some Romanian inflections that use ș and ț. About 0.9% of words in my Wiktionary sample and 1.8% of words in my Wikipedia sample were not being stemmed correctly, but now will be.
Our Romanian comma/cedilla problems are resolved, but I also opened tickets upstream for the stop word list in Lucene and for the Snowball stemmer to do the right thing—which is to include both ş/ș and ţ/ț, since they are all still in use, and it’s easy to not notice when you have the wrong one.
❦ Bengali/Bangla—Naughty Normalization, Shaken and Shtirred
When making the list of language analyzers that needed unpacking, I discovered that our then-newish version of Elasticsearch had two additional analyzers that we hadn’t enabled: Bengali and Estonian. Since they would have to be unpacked when they were enabled, I added them to my list of analyzers to work on. Enabling a new analyzer—particularly with a good stemmer, see footnote ** (there’s good stuff in those footnotes, I’m telling ya!)—is the best way to make a big impact on search for a given language, so it was an exciting prospect!
Many of the analyzers enabled for on-wiki search have been deployed for a long time, going back before my time at the Foundation, and so haven’t been explicitly tested or analyzed that I know of. Hence my getting (happily, if unexpectedly) sidetracked when I find something amiss, as with Turkish and Romanian above. So, for new analyzers, I like to give them a quick check to make sure they don’t do anything they obviously shouldn’t. I’ve found some weird stuff over the years.‡‡
I found a fair number of groups of Bengali words that had the same stem, but did not have any initial or final letters in common—a cause for extra attention, but not necessarily an error. The most common alternation was initial শ, ষ, স (shô, ṣô, sô). Using Wiktionary and Google Translate, things looked fairly suspicious, but neither is 100% reliable (especially in a writing system I don’t know). After consulting with some Bangla speakers, and looking at some clearly bad examples—like বিশ (the number “20”); বিষ (“poison”); বিস (“Lotus stalk”), which do not seem to be related at all—I decided to track down the source of the conflation in the Bengali analyzer.
The default Elasticsearch Bengali analyzer has a few extra components beyond the usual tokenizer, lowercasing, stop word filter, and stemmer. There are three components that do additional normalization:
- decimal_digit, which converts lots of non–Western Arabic numerals (see examples below) to Western Arabic numerals (0-9); it’s used in analyzers for six different languages, and seems to be a numeral-specific subset of ICU Folding
- indic_normalization, which “Normalizes the Unicode representation of text in Indian languages,” and is also used in the Hindi analyzer
- bengali_normalizer, which is specific to Bengali, and “Implements the Bengali-language specific algorithm specified in: A Double Metaphone encoding for Bangla and its application in spelling checker”

The paper title immediately set off some alarm bells for me, because Metaphone and Double Metaphone are well-known phonetic algorithms. Phonetic algorithms are designed to provide an encoding of a word based on its pronunciation.§§ I reviewed the algorithm in the paper with our team’s data analyst, Aisha Khatun, who also happens to speak Bangla. She said that none of the rules should be applied to all words, or even most words (for search indexing), because they are based on the sound of the letters. That sounds like an excellent algorithm for making spell check suggestions—and indeed the first sentence of the paper’s abstract is “We present a Double Metaphone encoding for Bangla that can be used by spelling checkers to improve the quality of suggestions for misspelled words”—but that’s not a good algorithm for matching search terms.
I disabled the bengali_normalizer as part of the unpacking.
The effect of introducing a new analyzer—mostly the stemmer—was huge! Bengali Wikipedia had a very high zero-results rate (49.0%), and the new analyzer provided results for about ⅐ of zero-results queries, lowering the zero-results rate to 42.3%—which is still fairly high, but definitely better. The overall number of non–zero-results queries that got more results right after introducing the analyzer was 33.0%—so ⅓ of queries got more results, too!
❦ Arabic, Arabic, & Arabic—Reusing Resources, Sharing Success
When unpacking the Arabic analyzer I asked Mike Raish from the WMF Design Research team to help me out with making sure all of the Arabic characters modified by ICU Folding were appropriate in an Arabic-language context. Everything was indeed copacetic!
As I was working to deploy the unpacking changes for Arabic (language code ar), I noticed some wikis with the language codes ary and arz—which turn out to be the codes for Moroccan Arabic and Egyptian Arabic. I did a little research and discovered that it was at least plausible that the Standard Arabic analyzer—or at least some of its components—could work for the other Arabic varieties.‖‖
Mike helped me to go into much more depth to review the stop word and stemmer components for use on those two wikis, and they were working well. We greatly expanded the stop word list, including additional orthographic variants and words with prefixes.
When the changes were deployed, there were huge improvements in zero-results rate! About 1 in 5 former zero-results queries on Moroccan Arabic Wikipedia (55.3% to 44.8%) now get results, and more than 1 in 3 on Egyptian Arabic Wikipedia (54.5% to 34.2%) now get results! Similar proportions of all queries get more results, too—1 in 5 for Moroccan Arabic Wikipedia and 1 in 3 for Egyptian Arabic Wikipedia.
❦ Foldy McFolderson and Friends
As noted above, unpacking analyzers so they each conform to their corresponding default bundled analyzer configuration would have no net effect on the output of the analyzer—they are the same processes, just specified explicitly rather than implicitly. However, our standard upgrades—ICU Normalization, ICU Folding, and homoglyph handling—can result in improvements in zero-results rate and number of results returned.¶¶
Typically, the biggest impact from ICU Folding comes from ignoring foreign diacritics. For example, on English Wikipedia, searching for Muju Dogyo, without ICU Folding enabled, would get zero results. With ICU Folding, it matches Mujū Dōgyō, and (currently) gets two results. Typing ū and ō is hard on most European-language keyboards, because the letters are not frequently used outside of Romanized Japanese or some sort of technical use. More common Japanese words and concepts, like rōmaji and nattō, appear more frequently, especially in more relevant articles—and the always helpful WikiGnomes have created redirects from the diacriticless versions to the right place;## so ICU Folding doesn’t help much in those cases, though it doesn’t hurt either.
However, in some cases, it turns out that diacritics commonly used in formal writing in a language are not so commonly used in casual writing—especially when the letters with diacritics are not considered separate letters. For example, in Swedish, å is a distinct letter from a. Presumably they are obviously related, though—but give it another couple thousand years: most people seem to have forgotten that G was originally a variant of C. Compare Spanish, where á is an a with an accent on it, but still an a.
Wiki content is usually written more formally, but queries can be all over the place. It seems especially common for people to leave off diacritics that are technically required by their orthography, but which in practice occur in specific words or general patterns that are so common that no one is confused by the lack of diacritic. Some examples:
- Acute accents in Spanish often indicate unpredictable stress, but even as a fair-to-middling Spanish speaker, I have never questioned where the stress goes in Jose Gomez de Peru (perhaps more formally known as José Gómez de Perú); Spanish searchers don’t type them all the time
- Irish searchers agree that some names, like Seamus Padraig O Suilleabhain, don’t need accents to be clear, though the WikiSticklers almost always write it more formally as Séamus Pádraig Ó Súilleabháin
- Portuguese searchers don’t always bother to type tildes, especially in são (often “saint”, commonly used in place names, like São Paulo)
- Catalan searchers really don’t like to type the accent in -ció (which is cognate with Spanish -ción and English -tion); Galician searchers, too, frequently type -cion for -ción
- It technically needs the accent to follow the stress rules, but it’s such a common ending that no one is going to mistake it for something else without it, in the same way an English speaker is never going to pronounce -tion as “tee-on”
- Basque searchers unsurprisingly search for Spanish words fairly frequently, but also fairly unsurprisingly, they don’t always type the accents
❦ Hindi—Transliterated Texts & Keyboard Capers
Unfortunately, neither ICU Folding nor any of the other general upgrades made much of an impact on Hindi Wikipedia queries. A few other languages had similar low-impact outcomes. It happens.
What made the Hindi data stand out was how incredibly high the zero-results rate is, with or without ICU Folding. The typical zero-results range for a large Wikipedia is 25% to 35%.◊◊ Hindi’s was over 60%! Since I had a reasonable sample of queries in front of me, I decided to see if I could find any obvious way that something could have gone weirdly wrong.
Almost 85% of zero-results queries on Hindi Wikipedia are in the Latin script, and almost 70% of those obviously look like Hindi transliterated from Devanagari, and about 40% of those get some results when transliterated back (I used Google Translate, just as a quick way to test). So, very roughly, almost ¼ of non-junk zero-result queries on Hindi Wikipedia could be rehabilitated with some sort of decent Latin-to-Devanagari transliteration! (It’s on our list of future projects.)
❦ Of Thai and Tokenization
Thai is generally written without spaces between words, so tokenizing it—breaking it into words—is a challenge. Among the default Elasticsearch pre-bundled analyzers, Thai is the only one not to use the standard tokenizer;☞☞ it uses a custom Thai tokenizer instead. The Thai tokenizer presumably uses a dictionary and some heuristics to find word boundaries in Thai text.
In my analyzer analysis, I discovered that the Thai tokenizer does quite a few non-Thai things differently from the standard tokenizer. It allows tokens with double quotes in them (e.g., the typo let"s); it also allows hyphens,*** en dashes, em dashes, horizontal bars, fullwidth hyphen-minuses, percent signs, and ampersands. The standard tokenizer splits words on all those characters.
More importantly, though, the Thai tokenizer can get confused by zero-width spaces, which are reasonably common in Thai text (at least on our wikis). The tokenizer seems to get into some broken non-parsing state until it hits a space or other character that is clearly a word boundary. The result can be really long tokens. The longest was over 200 characters! (With the zero-width spaces removed, it parsed into 49 words—20 of which were then dropped as stop words.)

There are two obsolete Thai characters, ฃ and ฅ, that have generally been replaced with the similar looking and similar sounding ข and ค, respectively. These obsolete characters also tend to confuse the Thai tokenizer, again causing it to generate really long tokens.
The Thai script is derived from the Old Khmer script, and so shares some of modern Khmer’s code point–ordering and glyph-rendering problems—fortunately on a much smaller scale! (I was really worried for a moment, since I spent a loooooooong time sorting out the most common Khmer ordering problems.)
As an example, here are four sequences of characters that can look the same, and how often they appeared on Thai Wikipedia at the time of my investigation:
- กล่ำ = ก + ล + ่ + ำ (8900 occurrences)
- กลํ่า = ก + ล + ํ + ่ + า (80 occurrences)
- กล่ํา = ก + ล + ่ + ํ + า (6 occurrences)
- กลำ่ = ก + ล + ำ + ่ (2 occurrences)
Since your glyph-rendering mileage may vary wildly depending on your fonts, operating system, and browser, below is a screen shot of the same characters as above, rendered on a MacBook in the Helvetica, Microsoft Sans Serif, and Sathu fonts (and in Everson Mono on the left for the character-by-character breakdown).

The top two versions of the word, which are the most common, render the same in more than a dozen fonts that I tested. The third variant often renders the same, as in Sathu, but sometimes differently, as in Microsoft Sans Serif (note that the diacritics are swapped), and sometimes brokenly, as in Helvetica. The fourth one rarely renders the same as the others, though it does in Sathu; it often renders differently, as in Microsoft Sans Serif, and sometimes brokenly, as in Helvetica. (Note that the broken renderings in Helvetica are arguably the most correct, because the diacritics are not being applied in the “correct” order, according to the Unicode Standard.)
All of this variation—as with Khmer (which has oh so much more going on!)—is bad for search because words that look the same are actually spelled differently. As an analog in English, this is like c+l+a+y, c+a+l+y, and c+l+y+a all looking like clay when printed. And, of course, these non-canonically ordered characters can confuse the Thai tokenizer—because not every variant would be in its dictionary—and cause it to generate more of those really long tokens.
It wouldn’t be so terrible if the Thai tokenizer could skip over obsolete characters or incorrectly ordered diacritics—they are basically typos, after all—and start picking out words on the other side; it’s the fact that it just sort of gives up and treats everything nearby as one really long token that is so bad.
Enter the ICU Tokenizer! The ICU Unicode components cover not just ICU Normalization and ICU Folding—there is also an ICU tokenizer. It has some dictionaries and/or heuristics for a fair number of spaceless East Asian languages, including Thai, Chinese, Japanese, Korean, Khmer, Lao, and others, so it provides decent parsing of those in a single package deal.
Comparing the two tokenizers, I discovered a few new things:
- The Thai tokenizer treats some symbols & emoji—as well as Ahom (𑜒𑜑𑜪𑜨), and Grantha (𑌗𑍍𑌰𑌨𑍍𑌥) text—essentially like punctuation, and ignores them entirely; it also inconsistently ignores some New Tai Lue (ᦟᦲᧅᦷᦎᦺᦑᦟᦹᧉ) tokens.
- The Thai tokenizer breaks up really long lines of text into 1024-character chunks, even if doing so splits a word in half!
- The ICU tokenizer doesn’t separate Thai or Arabic numbers from adjacent Thai words; this is reasonable in languages where words have spaces between them and the numbers are likely to be intentionally attached to the words—so 3a really is 3a and not 3 + a—but it is less reasonable in Thai.
The ICU tokenizer seems to actually be better for Thai text than the Thai tokenizer, and its comparative shortcomings (e.g., #3 above) can be remedied with a few additions to the unpacked Thai analyzer to strategically add spaces in the right places.
However, the ICU tokenizer has some additional known problems. The most annoying to me—given that homoglyphs are my personal nemesis—is that it explodes mixed-script tokens, so that our frenemy chocоlate—where the bold character in the middle is Cyrillic—gets split into three tokens: choc, о, late. Split like that, they can’t be repaired by our homoglyph handling upgrades. (It also splits non-homoglyph mixed-script tokens like KoЯn into Ko + Я + n.)
Arguably more incorrectly, the ICU tokenizer also does some weird things with tokens that start with numbers, in certain contexts. As an example, x 3a is parsed as x + 3a (because x and a are both Latin characters) while ร 3a is parsed as ร + 3 + a (because ร and a are not in the same character set—yeah, it’s weird).
After enabling the ICU tokenizer and adding some extra steps to remove zero-width spaces, replace obsolete characters, and reorder diacritics, my Thai Wiktionary sample had 21% more tokens, and my Thai Wikipedia sample had 4% more tokens. There was also a drastic decrease in the number of distinct tokens—down about 60%. The average length of distinct Thai words also dropped, from 7.6 to 5.1 for the Wikipedia sample. All of these are indicative of longer phrases being broken up into separate words, most of which occur elsewhere in the text. As an analog in English, myThaiWiktionarysample would be one longer, unique token, while my + Thai + Wiktionary + sample results in four shorter tokens that all occur elsewhere.
When looking at the effect of the ICU tokenizer after deployment, I discovered that in addition to making ridiculously long tokens, the Thai tokenizer sometimes makes ridiculously short tokens, breaking some text up into single Thai characters. This can result in lots of false positive matches. For comparison, the word Thai will only match a small fraction of articles in English Wikipedia, but if we indexed individual letters, then searching for t, h, a, and i would match almost every article in the wiki!
So, for the first (and so far only) time, the zero-results rate had a net increase after unpacking, upgrading, and modifying an analyzer—by 1.5%—due to the effects of the ICU tokenizer. About 0.5% of queries went from zero results to some results—mostly because really long tokens where broken up—and about 2% of queries went from some results to zero results—mostly because words weren’t being broken up into single letters anymore.
❦ Irish—Dotty Dots & Overdots
Older forms of Irish orthography used an overdot (ḃ, ċ, ḋ, etc.) to indicate lenition, which is now usually indicated with a following h (bh, ch, dh, etc.).††† It was easy enough to add the mapping (ḃ → bh, etc.) to the unpacked Irish analyzer. Since these are not commonly occurring characters, it didn’t cause that many changes, but it did create a handful of new good matches.
Another feature of Gaelic script is that its lowercase i is dotless (ı). However, since there is no distinction between i and ı in Irish, i is generally used in printing and electronic text. ICU Folding already converts ı to i.
The Irish word amhráin (“songs”) appeared in my sample corpus both in its modern form, and its older form, aṁráın (with dotted ṁ and dotless ı). Adding the overdot mapping plus and ICU Folding allows these two forms to match!
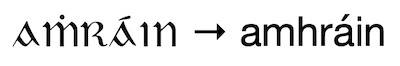
The Future—Living in Harmony
Unpacking all of the monolithic language analyzers is one step—but by far the biggest step!—in a larger plan to harmonize language analysis across languages and wikis. That doesn’t mean to make them all identical, of course.¶¶¶ There will always be language-specific processing on some wikis—in fact, we love language-specific processing, I wish we could do it for more wikis!### And, of course, it makes sense to err on the side of the “home” language of a wiki, and process text in the way that works best for that language.
What doesn’t make sense is that Mr.Rogers, Mr_Rogers, and MrRogers get treated differently on different wikis, before any language-specific processing might happen, and they may or may not match Mr. Rogers in different places. Or that D'Artagnan matches D’Artagnan on some wikis, but not others. Or that chocоlate—where that dang bold character in the middle is still Cyrillic—matches plain chocolate on one wiki but matches mixed-script lateоchocΔΔΔ on another.
All of the non–language-specific processing across wikis should be as close to the same as possible, with any deviations motivated by some language-specific concern, not the historical happenstance of analyzer development and deployment. And once the language analyzers are as harmonious as they can be, it’ll be easier◊◊◊ to make improvements across all languages.↓↓↓
Coda—Notes and Footnotes
If this ridiculously long blog post somehow leaves you wanting more, then you should seek professional help then you can always check out my Notes pages on MediaWiki. I have an even ridiculously longer page with all my Unpacking Notes, which includes less background but more technical details. I document most of my language- and search-related projects on MediaWiki, with links on my main Notes page.
Finally, before I go, I hope you enjoyed reading the footnotes half as much as I enjoyed writing them. You did read the footnotes didn’t you?☞☞☞
__________
* What is a computational linguist, you ask? Details vary from computational linguist to computational linguist,† but in my case, the short answer is, “a specialization of software engineer”. Eagle-eyed readers of my previous blogs will have noticed that my earlier bylines have said “software engineer” rather than “computational linguist”. Both are correct, but “computational linguist” is more specific.
† The thing that happens when you hear or see a word over and over and it loses its meaning is called semantic satiation. Computational linguist, computational linguist, computational linguist.
‡ I’m probably not supposed to have a favorite—but one of the worst kept secrets in the world is that Wiktionary is my favorite. Don’t tell the other projects.
§ The exact count is always subject to change because new analyzers are added now and again, but it’s also just hard to count the existing “languages”. There are analyzers for Portuguese and “Brazilian” (a.k.a., Portuguese), which aren’t that different—two analyzers, one language. And there is the CJK analyzer, which provides some basic support for Chinese, Japanese, and Korean—three languages, one analyzer—though we only still use it for Japanese at the moment.
‖ Most languages use a standard tokenizer to find words, but Thai has its own tokenizer. The CJK analyzer doesn’t even try to find Chinese, Japanese, or Korean words; it just breaks CJK text up into overlapping character bigrams. Languages with writing systems that don’t have case distinctions, like Arabic, Bengali, or Chinese, still have a lowercasing step to handle foreign words, ’cause English is like a bad penny—it turns up everywhere. A handful of analyzers—Persian, Thai, and CJK—don’t include stemmers.
¶ And probably not that peasy, either. Nothing ever is.
# A fun challenge for word nerds: Can you name a dozen writing systems? Two dozen? Four dozen? Heck, make it an even 50! (Hint: Just the Brahmic scripts will get you ⅔ of the way there, and here’s a cheat sheet to get you to over 100!)
Δ It’d also be great if Hawai'i and Hawaiʻi could match Hawai′i, Hawai´i, Hawai῾i, Hawai‛i, and Hawai`i—all of which occur on English Wikipedia—but we aren’t there yet. Hawai*i, Hawai,i, and Hawai«i also occur on English Wikipedia, but I don’t even feel bad for not matching those. Also, if you’re curious, the apostrophe-like characters here are, in order of appearance: apostrophe ('), Hawaiʻian okina, a.k.a. “modifier letter turned comma” (ʻ), right curly quote (’), left curly quote (‘), modifier letter apostrophe (ʼ), modifier letter prime (ʹ), prime (′), acute accent (´), greek dasia (῾), reversed comma quotation mark (‛), and grave accent (`). In the “what the…?” section we also have asterisk (*), comma (,), and left guillemet («).
◊ A bit of software developer wisdom: there’s no such thing as a guaranteed “quick, simple fix”. Many simple fixes are indeed quick, but there are always some sort of shenanigans that could occur. There’s a reason why the 90-90 rule exists!
↓ For once, the major world languages were getting short shrift, instead of the smaller, generally less well-supported languages. Our default upgrades, like homoglyph handling and ICU Normalization (but not the more aggressive ICU Folding), are enabled by default for every language/wiki that doesn’t have a monolithic language analyzer.
☞ “Experience is what you get right after you need it.” Every time I find some weird or unexpected thing going on with a language or an analyzer, I update my scripts to highlight that potential problem in the future, so at least I don’t have to struggle to figure out that exact same issue again.
** In search, a 1% improvement in any standard measure—recall, precision, zero-results rate, etc.—is a pretty big deal. Search is generally very good, and usually we are working at the margins to improve things. The exceptions to this rule, within the realm of language analysis, is adding a stemmer where there was none before. English generally doesn’t have very much grammatical inflection—dog/dogs and hope/hopes/hoped/hoping are about it! The best/worst English can do is probably highly irregular be, with a measly eight forms: be, being, been, am, is, are, was, were. In the Romance languages, each verb may have around 50 conjugations (e.g., Fr. manger, 48; It. mangiàre, 58; Sp. comer, 68), and in Finnish, with its extensive case system, nouns may have thousands of forms, even if most are rarely used. Merging all those together with a stemmer can greatly improve the number of results you see for lots of queries.
†† Rules-based stemmers are relatively lightweight and cheap, and have been around forever. They don’t include extensive lists of exceptions (like Dutch/Holland or be/been/being/am/is/are/was/were), but they can help immensely for many languages.
‡‡ A few examples: One analyzer converted all punctuation to commas and indexed them. (Punctuation is usually discarded at indexing time.) The result was that any punctuation in a query matched all punctuation in the entire wiki. Another stemmer transliterated Cyrillic to Latin, since the language used both, but because of the way the code was written, it accidentally threw away any text that wasn’t Latin or Cyrillic, instead of letting it pass through unchanged. Another statistical stemmer had a problem with foreign words and numbers and ended up conflating hundreds of random words and names together. All of these were mostly or completely fixable with various patches to code or config.
§§ Phonetic algorithms have been used in spell checkers—for example, to help people spell genealogy correctly—and in genealogy to group similar-sounding names—for example, to match the many spellings of Caitlin… though few will have any chance of matching KVIIIlyn—but I digress.
‖‖ You never can tell based on the names of languages how closely related they are. There’s an old joke that “a language is a dialect with an army and navy”—the distinction between closely related “languages” is often social or political. The so-called “dialects” of Chinese are approximately as distinct as the Romance languages, while Bosnian, Croatian, and Serbian are approximately as distinct as some dialects of English and are generally mutually intelligible.
¶¶ They can also affect ranking and what specific text is chosen for a given snippet shown with results on the Special:Search page. I generally look at changes to the top result, though that can be somewhat noisy for less common words and/or smaller wikis because of the way that word statistics are calculated. To wit, different search shards in our search cluster will have slightly different word statistics, based on the specific documents stored in each shard. In some fairly rare cases, the ranking scores for the top few documents are so close that teeny, tiny differences in word statistics between servers that would normally be a rounding error in the match score can end up being enough to affect the final result order. Reloading the page might give you results from a different search server, where those teeny, tiny differences result in a couple of top-5 results swapping places. This is most likely to happen with a very uncommon search term that appears only once or twice in each of only a dozen or fewer documents, and not in the title of any of them. I don’t usually look at other ranking changes or snippet changes unless there’s some reason to think something has gone weirdly wrong.
## The WikiGnomes are awesome, and we should all appreciate them more. Often, if I give an example of something that doesn’t work quite right on-wiki in a blog post or Phabricator ticket or email list, some kind WikiGnome will fix it out from under me—which I love. One of my favorite instances was on a completely unrelated project years ago; we were discussing (and lamenting) on Phabricator how there was no obvious good result for the query naval flags on English Wikipedia and… to make a long story shortΔΔ… Thryduulf went and created a good disambiguation page for naval flag, with a redirect from the plural, and a link to a new Lists of naval flags page, too. Now there is an obvious good result for the query naval flags!
ΔΔ Which, obviously, goes against my very nature.
◊◊ Back in my early days at the Foundation, I used to worry that this was kind of high—as did many other people. In 2015, I went looking into the zero-results queries across lots of Wikipedias, to see if I could see any obvious places for big improvements (or even little ones—again, see footnote **). I did uncover a bug in the Wikipedia Mobile App that got fixed, but I also found a lot of dreck that really doesn’t deserve results. There are bots and apps that do loads of automated queries. Sometimes the bots can be more than a little random—bad programmer! bad!—but we try not to worry about it unless it gets abusive. Some apps seem to be fishing for something useful to show their users, but it’s okay if they don’t find anything. (And in general, it’s always awesome that people are building on top of the free knowledge platform that we provide!) Programmers make some mistakes, like literally searching for {searchTerms} instead of the actual search terms, or repeatedly over-sanitizing data so that "search" (with straight quotes) ends up being queried as quot search quot (probably with an intermediate form like "search"). And of course, human searchers make mistakes, pasting the wrong thing into the right search engine, or maybe the right thing into the wrong search engine—we get lots of searches for gibberish, or giant excerpts of text (i.e, 1,000-word queries, back before we put a length limit on it), or very non-encyclopedic queries more suited for a general web search engine (like dating advice, pornography, etc.).↓↓
↓↓ Despite this, people still want to mine commonly repeated zero-results queries for potential new articles. It’s a good idea—I certainly thought so when I had it, too. But in practice, on English Wikipedia at least, there’s really not very much there. I looked into that in 2016 and found a lot of porn. A lot of porn. I think that on bigger wikis the WikiGnomes move faster than anyone could review zero-results queries, especially with making new redirects. Also, many queries that don’t go to the exact right place don’t actually get zero results—when you have millions of articles, it’s hard not to match something.
☞☞ The CJK analyzer generates bigrams for CJK text, which is quite different from standard tokenization, but it does use the standard tokenizer as a first step, which handles a lot of non-CJK text. A later cjk_bigram step re-parses sequences of CJK tokens into overlapping CJK bigrams.
*** I also learned that the usual hyphen, which also functions as a minus sign (- U+002D “HYPHEN-MINUS”) and which I thought of as the hyphen, is not the only hyphen… there is also ‐ (U+2010 “HYPHEN”). Since I had been labelling the typical “hyphen-minus” as “hyphen” in my reports, it took me a while to realize that the character called just “hyphen” is distinct. Fun times!
††† This borders on an orthographic conspiracy theory, but overdots being converted to –h in Irish got me thinking about how h is used in several European languages to indicate that something is a related sound that there isn’t any other good way to write. English does this frequently, with ch, sh, th, and zh, and sometimes kh—plus maybe wh, depending on your accent, and ph, even though we have f just sitting there.‡‡‡ French uses ch and German uses sch for the sound we write in English as sh. Polish and Hungarian also like z as a “similar sound” marker. Other digraphs§§§ are a little more combinatorial, such as when dz sounds more or less like d + z.
‡‡‡ There are etymological reasons—mostly Greek—for many instances of ph instead of f, but English spelling is so terrible that I’m not really sure it was worth it.
§§§ It’s fun—for some word nerd definition of fun—to look up digraphs, trigraphs, tetragraphs, pentagraphs, and hexagraphs on Wikipedia. Note that most of the examples of pentagraphs and all the examples of hexagraphs are Irish. Irish spelling is one of the few on par with English spelling for horribleness orthographic depth.‖‖‖
‖‖‖ [The tangent goes wild!] An interesting case of asymmetric multilingual orthographic depth is the Santa Cruz language, which is also called Natügu, which is also spelled Natqgu. Its orthography is very “shallow”, with a firmly enforced “one letter, one sound” principle. However, in the 1990s, they decided to get rid of diacritical letters that were then hard to type, publish, or photocopy locally and replace them with easier letters—i.e., the ones on an American English typewriter that they weren’t using for anything else. As a result, c, q, r, x, and z are vowels in Natqgu—so, while the orthography is shallow, it is also fairly opaque to most other users of the Latin Alphabet. See “When c, q, r, x, and z are vowels: An informal report on Natqgu orthography” (~400K PDF) for more!
¶¶¶ It would have been so quick and easy to just have one analyzer for everything—but it would have been terrible at everything.
### And I’m always looking for ways to do more. Over the years we’ve made upgrades and improvements to Chinese, Esperanto, Hebrew, Khmer, Korean, Mirandese, Nias, Polish, Serbian & Croatian, Slovak, and Ukrainian. Some of those have been driven by the availability of open-source software, some by Phabricator tickets reporting problems, and some by motivated volunteers who speak the language. If you know of good open-source language processing software—especially stemmers—that could be wedged into our tech stack (I’m pretty handy with a hammer!), or you’ve found a smallish problem or task—smaller than stemming, say—that we could possibly address, open a Phab ticket and @ me. (The ghost of every Product Manager I’ve ever worked with reminds me that I can’t promise that we’ll get to your ticket the same year hemi-decade you open it, but I’ll try to do what I can.)
ΔΔΔ Because of that ICU tokenizer bug, both chocоlate and lateоchoc get broken up into three tokens, choc + о + late. The fact that they are out of order is usually less important to matching than the fact that they are very close together. The fact that they don’t have spaces between them matters not a whit.
◊◊◊ That’s a huge step up! Before unpacking, making improvements across all languages together wasn’t even possible.
↓↓↓ Another of my personal bug-a-boos has been the fact that searching for NASA doesn’t find N.A.S.A., and vice versa. And I really want to get all the (reasonable—see footnote Δ) variants of Hawaiʻi matching each other. I wish I could fix everything, everywhere, all at once!
☞☞☞ Like my footnote symbols? Hate ’em? Hey, I’m just trying to bring back the classics!
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation