
Projects supported by the Wikimedia Foundation, such as Wikipedia, are among the most used online resources in the world, garnering hundreds of billions of visits each year from around the world. As such, the Foundation has access to terabytes of Wikipedia pageview data. The Wikimedia Foundation releases data about pageviews of every Wikimedia project hourly and has been doing this for every public project for almost 20 years. Analyzed effectively, this user-derived data can provide a rich resource for understanding many topics: from user behavior and the dissemination of information, to epidemiology, to online harassment and browsing patterns.
Soon after the Foundation released the pageview API in 2016, we received several requests to make granular pageview counts available per project per country. While pageviews per project have proven very useful, projects roughly map to languages in the Wikimedia ecosystem, and countries and languages are very different.This is especially important for languages that are spoken in many countries, such as English, French, Spanish, Chinese, and more. Take, for example, traffic patterns on 24 February 2023, the day before the 2023 Nigerian elections. Our new data shows that on the English Wikipedia in Nigeria, 14 of the top 20 most-viewed articles were election-related. The winner of the election, Bola Tinubu, was the 5th-most-viewed article in the country. Across all of English Wikipedia, Tinubu ranked 850th. Many of Wikipedia’s editors work with a country-specific focus, and data points like this one help inform their efforts.
While the benefits of releasing this data to the broader community were easy to see, the task came with significant technical challenges. We want to ensure that the Foundation’s public data is equitable across all projects and countries, not just places with lots of traffic. Thus, we needed to solve the hard problem of how to release meaningful data for wiki projects with not a lot of pageviews, while respecting the privacy of all users.
In partnership with Tumult Labs, we adopted an approach based on differential privacy to release this data. Read on for more details about the rationale for the decision, a short introduction to differential privacy, and more details about the technical approach! Today, we are happy to announce that the Foundation has released almost 8 years of pageview data, partitioned by country, project, and page. Due to various technical factors, there are three distinct datasets:
The Wikimedia Foundation’s data policies
Privacy is a key component of the free knowledge movement, as there cannot be creation or consumption of free knowledge without a strong guarantee of privacy. These guarantees are expressed by the Foundation’s privacy policy and data retention guidelines — both of which were drafted in the open together with community input. The privacy policy and data retention guidelines govern how Wikipedia technical stack works and are the reason why, for example, Wikipedia does not run on top of any cloud provider (because per policy we do not send any data to third parties).
At the same time, the Foundation regularly releases data for research purposes. This process is driven and governed by the open access policy, which seeks to provide as much transparency as possible when it comes to data releases.
These policies, at their core, express conflicting organizational impulses: for the privacy policy and the data retention guidelines, a drive toward harm reduction for users and away from surveillance; for the open access policy, a drive toward transparency and a belief that the data we collect can improve our understanding of and engagement with the internet.
In the case of the pageviews per country dataset, these tensions are also apparent: we want to make this data available while making sure that browsing habits of frequent users are not exposed in this data release. Users and editors are pseudonymous for a reason. In spite of our best efforts to anonymize data, motivated actors could still combine our data with outside other data sources in order to spy on or persecute our users for their view history, edit history, or other behavior.
Differential privacy provides a way of easing this tension, allowing us to both lower and more fully understand the risks of releasing data.
What is differential privacy?
In this context, defining privacy in a rigorous and scientific way is key. This is where differential privacy is particularly well-suited. Differential privacy is a probabilistic way to bound an attacker’s information gain when releasing data.
Differential privacy provides a mathematical framework for providing statistics and information about a dataset while ensuring that no information is recoverable about any single individual in that dataset. Making a dataset differentially private involves adding a relatively small, measurable amount of random noise to the data.
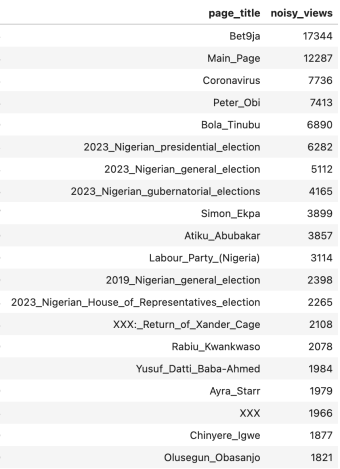
The notion of random noise is not one that is trivial to grasp so let’s work with a simpler example dataset. Say we have 1000 subjects and we want to figure out what fraction of them have ever vandalized Wikipedia. We want no harm to come to any of our subjects, so while we want to learn the answer to the question in aggregate, we do not wish to know every subject’s answer.
What do we do to solve this riddle? We can use a coin as a source of noise.
- We first ask every one of our 1000 subjects to flip a coin
- If they get heads, they should truthfully answer the question of whether they have vandalized Wikipedia (yes/no)
- If they get tails, we ask them to flip the coin a second time
- If they get heads, they answer yes
- If they get tails, they answer no
At the end of this process, we have 300 yeses and 700 nos.
When we look at the raw data, we can see that Alice’s answer was yes. Can we conclude that Alice did truly vandalize Wikipedia? No, because Alice’s answer might have been a result of flipping the coin twice.
Can we infer the real percentage of vandalizers? Yes, because we can estimate that on average, our system inserted 250 random ‘yes’ answers and 250 random ‘no’ answers. In that case, we can conclude that the true rate of vandalizing is (300 – 250) / (1000 – 250 – 250) = 50 / 500 = 10%.
Differential privacy does not provide a guarantee that the results of releasing a dataset won’t be harmful to Alice; just that no individual harm will befall Alice for adding her data to the dataset. For example, Wikipedia administrators may view this vandalism data and decide to block certain kinds of edits (which might impact Alice), but Alice’s participation in the dataset would have no bearing on the dataset output, and her information would not be leaked in the process. In practical terms it means that you cannot infer Alice’s answer from looking at the data.
Importantly, differential privacy provides a quantifiable amount of privacy loss for each dataset release. Unlike other existing forms of anonymization — k-anonymity, data sanitization, etc. — it allows for a precise measure of exactly how risky a data release is.This data release uses the same intuition as this toy example (but a different methodology, adding noise to the data after it has been collected), to achieve the same effect with counting pageviews per article per country per project. For more information about differential privacy in theory and in practice, see these two blog posts by Damien Desfontaines, a collaborator on this project: DP in theory, DP in practice.
Putting differential privacy into production
Over the past two years, the Wikimedia Foundation has developed a differential privacy infrastructure for the safe release of information that could otherwise be harmful to Wikimedia users. In this work we have partnered with Tumult Labs, an organization that makes open source differential privacy software that can handle the ~650 million rows of data that comprises our store of daily pageviews.
Over the course of a year, we built a new system for creating privatized data pipelines, and utilized it to create the three distinct datasets linked at the top of this post. In each case, the process followed the same structure:
- Define the problem: Write and publish a problem statement, which lays out a rationale for the data release, the plan for releasing the data, a privacy unit, possible error metrics, and a pseudocode first draft of the algorithm to be used.
- Using default hyperparameters, see if it is possible to conduct a differentially- private data aggregation at all: Sometimes due to resource or infrastructure constraints it’s impossible to do a privatized aggregation at all — we won’t know until we try. It’s important to figure out what the script for an aggregation will look like. (example)
- Decide on error metrics to optimize for: Create a set of internal error metrics to evaluate the data release against. All differentially-private datasets have some noise added, but if the noise needed to provide privacy guarantees is too great, the dataset might no longer be useful. For example: median relative error, drop rate, spurious rate, etc.
- Experiment with a wide variety of hyperparameters until error metrics are optimized: Conduct a grid search of hyperparameters (output threshold, noise type and scale, keyset, etc.) until we find one that is optimal given the above error metrics.
- Productionize the pipeline: Turn the finalized aggregation into a finished script, integrate error calculation and privacy loss logging, and use Airflow to automate running the job regularly.
Differential privacy allows for the use of already-public data to improve the release. We used public pageview counts from the Pageview API to limit the number of pages we had to consider. After all of that, we ended up with a final pipeline that (conceptually) looked something like this:
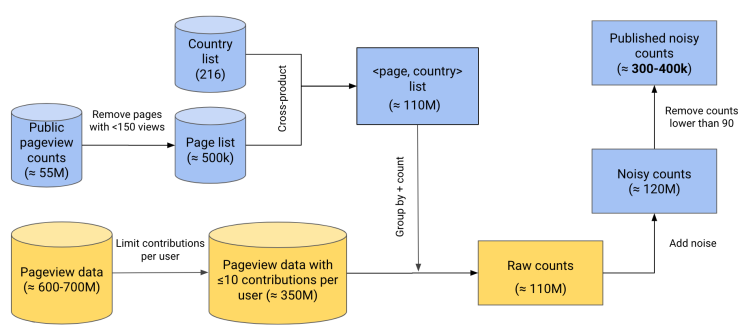
where private, sensitive data is in yellow and data that is already public is in blue.
For more information about the thinking behind these data releases and differential privacy at the Foundation, you can look at the problem statements (pageview, pageview_historical) or the differential privacy homepage.
To learn more about each individual data release, including details about keyset limiting, noise type and scale, and release threshold, please consult the release-specific READMEs.
And for a more in-depth dive into the technical details of this data release, please see Tumult Labs’ case study on this project.
Hal Triedman is a Senior Privacy Engineer, Isaac Johnson is a Senior Research Scientist, and Nuria Ruiz is the former Director of Analytics at the Wikimedia Foundation.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation