
.jpg){kind=link}
What would become of Wikipedia and its sister projects without images from museums, libraries, and archives? Pictures from these institutions are able to illustrate a range of different articles, in diverse fields and areas. However, in order to really accomplish that, images should not only be available, but also enriched with data that can make them more findable on the projects.
And so, for the past few years, the Culture and Heritage team at the Wikimedia Foundation has been involved with Structured Data-related initiatives in order to engage heritage materials on the Wikimedia projects. Our objective, together with the Structured Data Across Wikimedia (SDAW) team, was to support and increase image usage across the projects, as well as to structure Wikimedia to help it reach communities globally.
One of the main projects we worked on together was the initiative with the Digital Public Library of America (DPLA). This institution became one of the biggest Wikimedia Commons contributors, with 3.7 million images available on the project, by not only being the main institution in the United States directly uploading files to the platform, but also because of its structured data activities. Since 2020, DPLA has worked on adding and modeling structured data and engaging in discussions around the topic, precisely to make its files (the files from the 300 institutions that contribute to the DPLA’s Wikimedia pipeline) more findable and used on Commons, on Wikipedia, and elsewhere. Currently, DPLA presents around 15 million edits to 50-100 million structured data on Commons statements.
For the 2022 to 2023 fiscal year period, Dominic Byrd-McDevitt, DPLA’s Data and Partnerships Strategist, has been uploading and modeling these statements on Commons, as well as working with Lua-based templates to disseminate this work on the Wikimedia projects. For example, he developed a template that transforms structured data into the summary information shown for the file on Commons, rather than duplicating this information as wikitext. To learn more about the templates developed by DPLA, watch Dominic’s presentation during Wikimania 2023:
Follow this link to view all of the categories for the DPLA’s contributing institutions and files and, on this page on Commons, you can see the modeling guidelines used by DPLA.
This year, DPLA reached a total of 3,618,323 subject statements, greatly exceeding the goal in their grant proposal. These statements include data about copyright status, copyright license, RightsStatements.org statement, creators, subjects, identifiers, contributing institutions, description, title, and collection. These statements have been added with references that allow the user to identify where this data came from (the original institution) and links to the DPLA website.
DPLA’s digital asset pipeline was fully documented on GitHub, including the DPLA ingestion repo, documenting how Wikimedia markup is generated from item records, and ingest-wikimedia, which documents the upload and metadata synchronization.
DPLA also launched DepictAssist, a tool that suggests potential depicts statements, and continued to work on their image citation gadget, which draws from structured data statements. Their citation feature is expected to be completed soon, and earlier versions were shared with more than 100 people, in different events and conferences.
Finally, one of the most important achievements of DPLA’s Wikimedia initiative this year was the development of the DPLA’s Wikimedia Working Group, which became DPLA’s largest working group. It has members from several major US institutions, such as the National Archives and Records Administration, Boston Public Library, Harvard Library, National Agricultural Library, Washington State Library, and others. This group has been helping DPLA in their efforts to contribute to Wikimedia, even organizing a Coffee Chat.
While not part of his work at DPLA, it’s worth adding that Dominic also developed View it!, together with Jamie Flood and Kevin Payravi. This tool, which was also supported by the Wikimedia Foundation, is able to show Wikipedia users all relevant Wikimedia Commons media depicting or related to the article they are interacting with. View It! works by using structured data statements, especially the Depicts property (P180), to suggest those images. These suggestions are available on the top of a Wikipedia article, in a very user-friendly way, or on other projects, such as Wikispecies, Wikivoyage, etc, and even on the View it! separate interface on ToolForge as well.
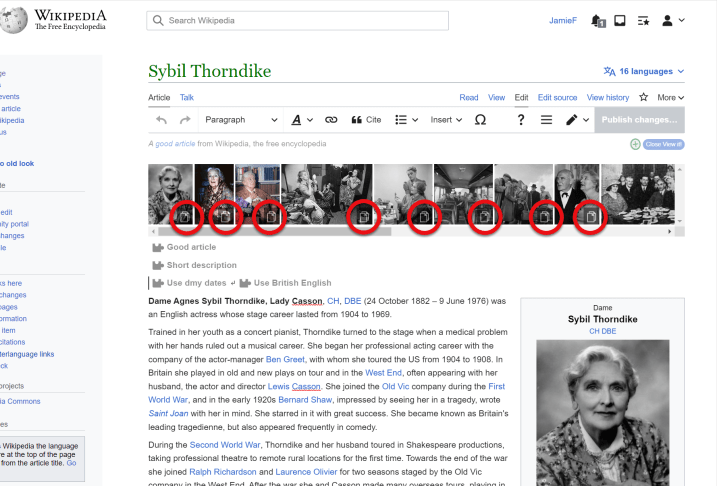
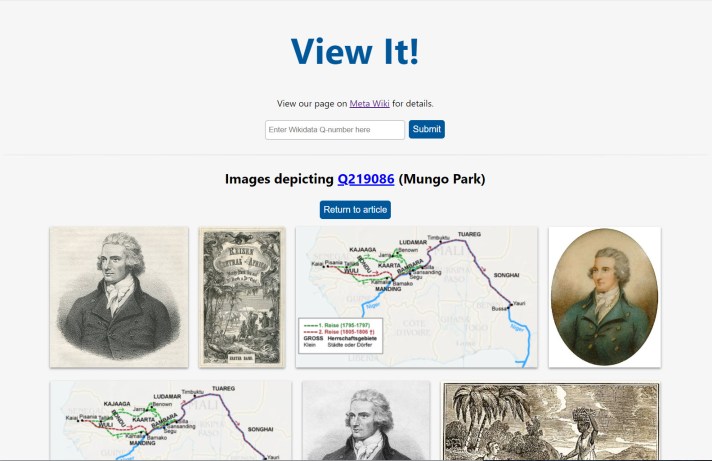
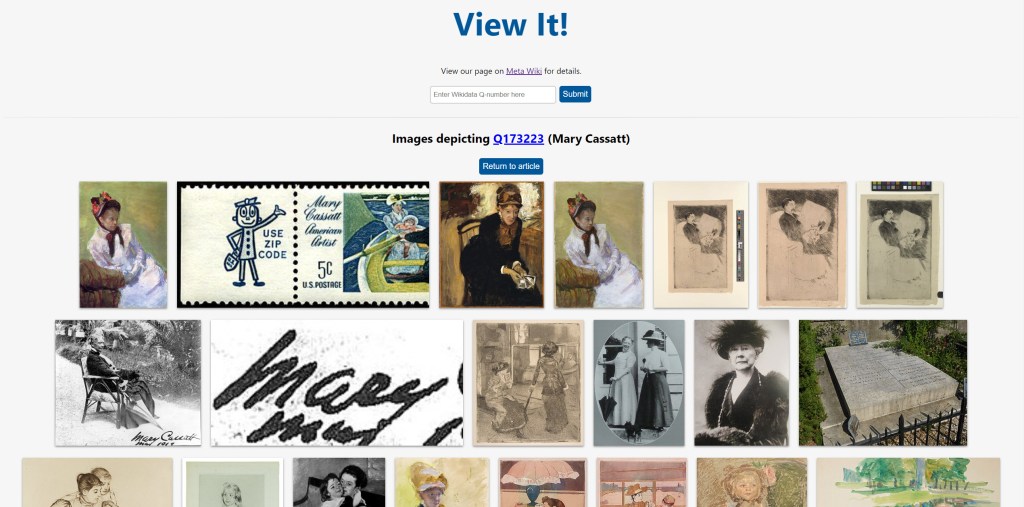
To learn more about DPLA’s collaborations with the Wikimedia movement, see their own project announcements:
- Leveraging Wikimedia for increased visibility + upcoming coffee chat
- DPLA to make cultural treasures freely available on Wikipedia with new Sloan Foundation support
- DPLA expands Wikimedia work
- Wikimedia Project update
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation