Hallo! Ich bin Trey und arbeite als Computerlinguist* im Team der Wikimedia-Suchplattform. Ich sage gerne, dass meine Aufgabe im Suchteam darin besteht, die Sprachverarbeitung für die Suche zu verbessern – vor allem für andere Sprachen als Englisch. Das ist nicht das Einzige, was ich tue, aber es ist mit Sicherheit meine Lieblingsaufgabe. Ich möchte dir von dem Projekt „Entpacken von Sprachanalysatoren“ erzählen, an dem ich in den letzten Jahren gearbeitet habe, um die Suche in einigen Dutzend Sprachen zu verbessern und die Suche in allen von uns unterstützten Sprachen zu harmonisieren. Dabei habe ich einige interessante Fakten über die verschiedenen Sprachen herausgefunden und einige lästige Fehler in den Analyseprogrammen aufgedeckt. Komm und verschaffe dir einen Überblick über das Projekt und nutze die Gelegenheit, die Sprache in ihrer fast unendlichen Vielfalt zu schätzen!
Präludium – Sprachanalyse
Die Sprachanalyse ist eine Reihe von Schritten, um Texte – wie Wikipedia-Artikel – für die Indizierung durch eine Suchmaschine vorzubereiten. Sie kann eine allgemeine Textverarbeitung oder eine sprachspezifische Verarbeitung umfassen, und beides kann ziemlich einfach oder ziemlich komplex sein. Anfragen von Suchenden werden auf ähnliche Weise verarbeitet, so dass der Text einer Anfrage mit dem Text im Suchindex verglichen werden kann.
Die Suche im Wiki für Wikipedia, Wiktionary‡ und die anderen sprachspezifischen Projekte wird von CirrusSearch bereitgestellt. CirrusSearch ist eine MediaWiki-Erweiterung, die derzeit auf der Suchmaschine Elasticsearch aufbaut, die wiederum auf der Suchbibliothek Apache Lucene basiert.
Lucene bietet Komponenten für die Sprachanalyse in etwa drei Dutzend Sprachen.§ Die meisten Sprachanalysatoren haben ein paar Standardkomponenten:‖
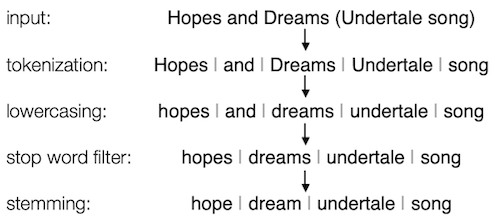
Tokenisierung — der Text wird in der Regel in Wörter zerlegt, mehr oder weniger
Kleinschreibung von Wörtern — so dass die Suche nach einem der Wörter gehen, GEHEN und Gehen auch die anderen findet
Filterung von Stoppwörtern — so dass Wörter wie das, von, ist, und, und andere ignoriert oder ausgeklammert werden
Stemmer — die sich dem Wortstamm annähert, so dass die Suche nach einem der Wörter hoffen, hofft, hoffte und hoffend auch die anderen findet
Viele Sprachanalysatoren verfügen über zusätzliche spezialisierte Formen der Normalisierung, die in der Regel darin besteht, bestimmte Zeichen in verwandte Zeichen umzuwandeln, die standardmäßiger sind oder mit denen man leichter arbeiten kann; die Kleinschreibung ist eine Art der Normalisierung. Mehrere Sprachen haben eine Elisionsverarbeitung, so dass z. B. im Französischen l’élision mit élision übereinstimmt. Türkisch hat eine andere spezielle Art der Apostrophbehandlung, über die wir später noch sprechen werden. Wenn du mehr – viel mehr – über Tokenisierung, Normalisierung, Stemming und Stoppwörter wissen willst, lies meine Blogserie über Die Anatomie der Suche.
Um die Implementierung und Konfiguration zu erleichtern, werden die Standard-Analysekomponenten für jede Sprache von Elasticsearch als vorkonfigurierter Analyzer gebündelt. Anstatt alles, was du brauchst, selbst zu konfigurieren, kannst du eine ziemlich gute Sprachanalyse für Armenisch, Baskisch, Tschechisch, Niederländisch, Estnisch, Finnisch, Griechisch, Ungarisch, Indonesisch usw. erhalten, indem du einfach den Namen des gewünschten Sprachanalysators angibst. Kinderleicht!
Normalisierung – Ich sehe dich, Unicode
Die Realität ist jedoch nicht ganz so einfach.¶ Große Wiki-Projekte haben Texte in vielen verschiedenen Sprachen – die mehrere Dutzend Schriftsysteme# verwenden – sowie technische Symbole, ungewöhnliche Zeichenvarianten und alle Arten von „interessanter“ Formatierung und Typografie. Wir wollen, dass diese Dinge für die Suchenden so transparent wie möglich sind.
Wenn jemand zum Beispiel sucht nach-
- … chu Quoc ngu, dann wollen wir, dass sie mit chữ Quốc ngữ übereinstimmen – vor allem auf Wikis, wo man nicht erwarten würde, dass Suchende vietnamesische Tastaturen benutzen.
- … βαρβιτιστησ – weil sie keine griechischen Akzente schreiben können, die Endung σ/ς im Griechischen vergessen haben und keine Ahnung von der französischen Angewohnheit haben, ϐ für β in der Mitte eines Wortes zu verwenden – wollen wir, dass sie βάρϐιτιστής entsprechen
- … Hawai'i, wollen wir, dass sie dem korrekteren Hawai’i, Hawai‘i, Hawaiʼi und HawaiʹiΔ
- … Wikipedia, mit Zeichen in voller Breite wollen wir, dass sie mit Wikipedia übereinstimmen, und wenn sie nach ウィキペディア in halber Breite suchen, wollen wir, dass sie mit ウィキペディア übereinstimmen
- … so ziemlich allem, wollen wir, dass sie Wörter mit unerwarteten unsichtbaren Zeichen abgleichen, wie z. B. Bidirektionalzeichen von links nach rechts und von rechts nach links, weiche Bindestriche, Variationsselektoren und verschiedene „Joiner“- und „Non-Joiner“-Zeichen
Glücklicherweise stellt das Open-Source-Projekt International Components for Unicode (ICU) Bibliotheken zur Verfügung, die diese Art von Unicode-Normalisierung unterstützen und in Elasticsearch-Plugins verpackt wurden. Zwei davon sind für uns besonders nützlich: ICU Normalization und ICU Folding.
ICU Normalization macht viele nützliche Dinge:
- einige weniger verbreitete Schriften und seltene Zeichen richtig klein zu schreiben (siehe Beispiele unten)
- Konvertierung von manchmal visuell nicht unterscheidbaren Zeichen (je nach Schriftart), wie µ → μ, ﯼ → ی, ㄱ → ᄀ, und ̀ → ̀
- die Umwandlung zahlreicher Zeichen in „normalere“ Formen, wie ſ → s, ϐ → β, ς → σ, ﹖ → ? und ︵ → (
- Streichen der oben genannten unsichtbaren Zeichen

[Hinweis: Da die Kleinbuchstaben der Cherokee-Schrift nur selten verwendet werden, werden sie in Großbuchstaben umgewandelt.]
Die vollständige Liste scheint nirgendwo dokumentiert zu sein, also habe ich sie im Jahr 2020 mit roher Gewalt herausgefunden. Ich fand heraus, dass die ICU-Normalisierung nicht perfekt ist, aber eine Menge Gutes bewirkt!
ICU Folding hingegen ist viel aggressiver und scheint jedes Zeichen auf seine einfachste Form reduzieren zu wollen – Diakritik hin oder her! Es wandelt zum Beispiel jedes à, á, â, ã, ā, ă, ȧ, ä, ả, å, ǎ, ȁ, ȃ, ą, ạ, ḁ, ẚ, ầ, ấ, ẫ, ẩ, ằ, ắ, ẵ, ẳ, ǡ, ǟ, ǻ, ậ, ặ, ⱥ, ɑ, ɐ, oder ɒ in ein einfaches a um. Als Englischsprachiger ist das genial, denn ich weiß kaum noch, wie man Biàncáitiān oder epäjärjestelmällistyttämättömyydellänsäkäänköhänkään buchstabiert, geschweige denn, wie man all diese akzentuierten Zeichen schreibt. In einem finnischsprachigen Wiki wollen wir jedoch in der Lage sein, a/ä & o/ö zu unterscheiden – und auch a/å. Schwedisch stimmt mit dieser Liste überein, während Dänisch und Norwegisch jeweils ihre eigene Liste von Buchstaben haben, mit denen man nicht herumspielen sollte. Baskisch, Galicisch und Spanisch wollen nur, dass n/ñ nicht vermischt wird. Thailändisch und Japanisch haben ebenfalls Listen, ebenso wie viele – vielleicht sogar die meisten – anderen Sprachen. Wir müssen also die ICU-Faltung für viele Sprachen sprachspezifisch anpassen, aber das ist es wert, denn es macht die Suche nach fremdsprachigem Text einfacher – wo es fremdsprachig ist, hängt natürlich vom Kontext des Wikis ab, in dem du dich befindest.
Neben den Verbesserungen, die die ICU-Komponenten bieten, haben wir auch andere Elasticsearch-Komponenten konfiguriert – oder in einigen Fällen unsere eigenen geschrieben -, um uns um andere „interessante“ Umstände zu kümmern, auf die wir im Laufe der Jahre gestoßen sind.
Wenn also jemand sucht nach –
- … ac bo wri mo, sollten sie mit AcBoWriMo übereinstimmen
- … Wikimedia Phabricator, sollten mit phabricator.wikimedia.org übereinstimmen
- … screaming snake case, sollten mit SCREAMING_SNAKE_CASE übereinstimmen
- … chocolate, sollten sie mit chocоlate übereinstimmen – wobei der fette Buchstabe in der Mitte des Wortes eigentlich ein kyrillisches Zeichen ist; solche Zeichen, die fast identisch aussehen, nennt man Homoglyphen, und sie sind meine persönliche Nemesis, wenn es um die Suche geht!
Monolithische technische Schulden – Entpacken
Leider können die von Elasticsearch bereitgestellten Standardkonfigurationen des Analyzers nicht mit ICU-Komponenten oder Komponenten, die wir selbst konfiguriert oder geschrieben haben, angepasst werden. Sie werden alle in einem Stück geliefert, daher die Bezeichnung monolithisch. Glücklicherweise gibt Elasticsearch die Komponenten jedes monolithischen Analyzers an und wir können sie als „benutzerdefinierte“ Analyzer wiederherstellen, die dann weiter modifiziert und aktualisiert werden können, um Probleme wie die oben genannten zu lösen.
In der Theorie ist das großartig und gibt uns jede Menge Flexibilität! In der Praxis hat sich dies jedoch als Hindernis erwiesen, wenn es darum geht, Verbesserungen vorzunehmen oder Fehler zu beheben, denn der erste Schritt zu einer ansonsten schnellen und einfachen Korrektur◊ ist oft das „Auspacken“ eines monolithischen Analysators.
Beim Auspacken überprüfen wir zunächst, ob der ausgepackte Analyzer die gleiche Leistung bringt wie der monolithische Analyzer, was ziemlich einfach ist. Wenn wir damit aufhören, müssen wir jedoch eine kleine Reihe von Standardverbesserungen deaktivieren, die wir für nicht-monolithische Analyzer haben, z. B. die Verwendung von ICU-Normalisierung anstelle von einfacher Kleinschreibung, die Aktivierung der Behandlung von Homoglyphen und ein paar Korrekturen für kleine Fehler, die wir in verschiedenen Analysekomponenten gefunden haben. Natürlich wollen wir all diese Upgrades aktivieren, aber sie erfordern ein paar Tests. Und wenn wir schon dabei sind, wäre es nicht toll, wenn wir die (entsprechend angepasste) ICU-Faltung aktivieren könnten? Natürlich wäre es das!

Nachdem wir über unser Ad-hoc-Auspacken einiger Analyzer nachgedacht hatten, wurde uns klar, dass monolithische Analyzer für uns eine technische Schuld darstellen – sie erschweren es, spezifische Verbesserungen für bestimmte Sprachen vorzunehmen, und sie hindern uns daran, allgemeine Verbesserungen überall auf einmal vorzunehmen.↓
Jetzt hast du hoffentlich eine bessere Vorstellung davon, was „Entpacken von Sprachanalysatoren“ bedeutet! Das unmittelbare Ziel war es, alle vorhandenen Sprachanalysatoren auszupacken, unsere Standard-Upgrades zu aktivieren und ICU Folding für jeden einzelnen zu aktivieren und anzupassen, und daran habe ich in den letzten zwei Jahren einen Großteil der Zeit gearbeitet.
Es war eine lange, seltsame Reise.
Testen, testen – ist das Ding an?
Im Laufe der Jahre, in denen ich mit Sprachen gearbeitet habe – beim Testen von Analyzer-Änderungen, bei der allgemeinen Analyse des Analyzer-Verhaltens und bei der Analyse großer Wikipedia- und Wiktionary-Beispiele – und bei dem Versuch herauszufinden, wie ich potenzielle Probleme am besten hervorheben kann,☞ habe ich einige Skripte entwickelt, die ich überflüssigerweise rekursiv wiederholend reduplikativ als meine „Analyse-Analyse“-Tools bezeichne.
Ich habe unter anderem gelernt, wie ich vorgehen und worauf ich achten muss:
- Gruppen von Wörtern, die denselben Wortstamm haben, aber keine gemeinsamen Anfangs- oder Endbuchstaben aufweisen. Manchmal ist das sogar ziemlich cool: Der englische Stemmer schreibt Niederländisch (engl. dutch) und Niederlande (engl. Netherlands) gleich, und Filipino und Philippinen gleich. Manchmal ist es aber auch ein Zeichen dafür, dass etwas schief gelaufen ist.
- Wirklich große Gruppen von Wörtern, die zusammen geschrieben werden. Manchmal handelt es sich um ein gemeinsames Wort mit vielen Formen. Manchmal handelt es sich um zwei oder mehr Wörter, deren Formen sich überschneiden. Manchmal ist das ein Zeichen dafür, dass etwas schief gelaufen ist.
- Sehr lange Wörter. Manchmal ist es nur eine etwas übertriebene deutsche Verbindung oder eine sehr große Zahl oder eine URL oder ein Satz in einer Sprache, die keine Leerzeichen verwendet, wie zum Beispiel Thai. Manchmal ist es aber auch ein Zeichen dafür, dass etwas schiefgelaufen ist.
- Unsichtbare Zeichen hervorheben. Wenn ein Wort mit einem weichen Bindestrich oder einer Links-nach-Rechts-Markierung versehen ist, wird es niemand jemals so schreiben, also ist es im Grunde unauffindbar!
- Farbcodierung von Token mit gemischter Schrift, damit man leichter erkennen kann, was los ist. Wenn ein Wort wie chocоlate einen nicht erkennbaren kyrillischen Buchstaben enthält, wird es niemand jemals so schreiben, also ist es im Grunde unauffindbar!

Ich schätze, es ist klar, dass ich ein bisschen besessen bin von Dingen, die im Grunde unauffindbar sind, und von anderen Fällen, in denen etwas seltsam schief gelaufen ist!
Natürlich ist es auch wichtig, alle Änderungen an einer Analysekette zu testen. Meine Analysewerkzeuge heben hervor, wo Wörter, die früher unterschiedlich waren, jetzt als dasselbe analysiert werden oder umgekehrt, ebenso wie Tokens, die früher existierten, jetzt aber nicht mehr, oder umgekehrt.
Ein weiterer Aspekt des Testens und der Analyse, den ich für dieses Projekt aufgegriffen habe, ist die Überprüfung der Änderungen in den Ergebnissen einer Stichprobe von Abfragen, nachdem Aktualisierungen vorgenommen wurden. Wenn ich mir die Änderungen in den Wikipedia- und Wiktionary-Beispielen ansehe, die ich vor dem Einsatz teste, gibt es genug Anhaltspunkte, um sicher zu sein, dass die Änderungen des Analysators korrekt sind. Der zusätzliche Schritt, die Abfragen nach der Bereitstellung zu prüfen, hilft dabei, den Einfluss der Änderungen zu beurteilen.
In der Regel kann der Abbau technischer Schulden zu keinen sichtbaren Veränderungen im Verhalten der Software führen – sauberer Code läuft vielleicht etwas schneller und ist definitiv einfacher zu handhaben, was sich bei der zukünftigen Entwicklung auszahlt. In diesem Fall jedoch bewirken ICU Normalization und ICU Folding oft eine kleine, aber deutliche Verbesserung** bei der Anzahl der Abfragen, die keine Ergebnisse liefern, und haben einen ähnlichen Einfluss auf die Anzahl der zurückgegebenen Ergebnisse im Allgemeinen. Ein Beispiel: Ohne ICU Folding wird die Suche nach Biancaitian keine Biàncáitiān finden. Es hängt von vielen Faktoren ab, ob ein Wort ohne seine bevorzugten diakritischen Zeichen in einem Wiki vorkommt, aber im Allgemeinen erhöht die Möglichkeit, ohne fremde diakritische Zeichen zu suchen (und ohne herausfinden zu müssen, wie man sie eintippt), die Zahl der nützlichen Ergebnisse.
Dieser zusätzliche Abfragetest hat den gesamten Entwicklungsprozess des Entpackens ein wenig verlangsamt, aber es ist schön, einen Eindruck davon zu bekommen, welchen Einfluss die Verbesserungen auf dem Weg dorthin haben.
Du sagst Anecdota, ich sage Anecdata
Wie oben und unten schon erwähnt, – wo wir von unten sprechen, du liest doch die Fußnoten, oder? Diese Fußnoten haben es in sich! Jedenfalls, wie oben und unten erwähnt, sind die Dinge oft nicht so einfach, wie man hoffen würde.
Bei meinen Tests und Analysen habe ich einige interessante Fakten über verschiedene Sprachen entdeckt und einige lästige Fehler in ihren Analyseprogrammen aufgedeckt. Lasst uns die Gelegenheit nutzen, die Sprache in ihrer fast unendlichen Vielfalt zu schätzen!
❦ Türkisch – die Angst vor nicht-muttersprachlichen Apostrophen
Apostrophe werden im Türkischen verwendet, um Eigennamen von angehängten Suffixen zu trennen – z. B. Türkiye’den („aus der Türkei“) – vermutlich, weil ohne Apostroph die Grenze zwischen einem unbekannten Namen und den Suffixen unklar sein könnte. Das Englische macht etwas Ähnliches mit a’s, i’s und u’s – den Pluralen von a, i und u – um sie von den Wörtern as, is und us zu unterscheiden.
Elasticsearch/Lucene behandelt Apostrophe speziell für das Türkische und entfernt den ersten Apostroph, den es in einem Wort findet, sowie alles, was nach dem Apostroph kommt. Das ist vernünftig für türkischen Text, aber es ist katastrophal für nicht-türkische Wörter und Namen wie D’Artagnan, d’Ivoire und d’Urbervilles – die alle zu d reduziert werden – oder O’Connell, O’Keefe und O’Sullivan – die alle zu o reduziert werden, was ein Stoppwort ist!

Da es viele Quellen und Online-Materialien in französischer Sprache gibt, taucht in der türkischen Wikipedia (und in vielen anderen Wikipedias) viel Französisches auf, und die Apostroph-Behandlung macht mit vielem davon gaaaanz schlimme Sachen. Noch schlimmer ist, dass der Apostroph nicht berücksichtigt, wenn es sich um nicht-lateinischen Text handelt, so dass einige sehr-nicht-türkische Wörter wie επ’ευκαιρία, прем’єр und ג’אלה ebenfalls mit einem Apostroph versehen sind.
Der türkische Apostroph wird auch für einzelne Buchstaben verwendet, egal ob es sich um den Buchstaben selbst oder um etwas handelt, das mit dem Buchstaben bezeichnet wird (z.B. „Gruppe B“), daher gibt es Formen wie B’dekilere („zu denen in B“). In meinen Daten ist d’ jedoch überwiegend ein Indikator dafür, dass etwas auf Französisch ist. Diese beiden Trends kollidieren in meinem Lieblingsbeispiel für türkische Apostrophe, d’nin. Sowohl d’ als auch ‘nin bedeuten „von“ – es ist also entweder französisch für „von nin“ oder türkisch für „von d“. Im Kontext eines türkischen Wikis scheint die Annahme, dass es sich um „von d“ handelt, die sicherere Variante zu sein.
Um nicht-türkische Wörter mit Apostrophen besser verarbeiten zu können – und türkische Wörter mit Nicht-Apostrophen, ähnlich wie in den Beispielen auf Hawai’i – habe ich einen Umweg über das Auspacken gemacht und einen neuen, besseren Apostroph-Handler entwickelt, der etwas selbstgefällig „better_apostrophe“ heißt.
Alle Fälle, Ausnahmen und Ausnahmen von Ausnahmen, die ich berücksichtigen musste, sind in der better_apostrophe ReadMe ausführlich beschrieben.
❦ Rumänisch – Cedillas & Kommas, verwirrt & verwechselt
Als ich mich über das rumänische Alphabet informierte – um zu erfahren, welche rumänischen Buchstaben von der ICU-Faltung ausgenommen werden müssen – erfuhr ich, dass es eine häufige Verwechslung zwischen ş und ţ (mit Zedille, nicht offiziell rumänische Buchstaben) und ș und ț (mit Komma, die richtigen rumänischen Buchstaben) gibt. Auf der rumänischen Wikipedia gibt es viele Beispiele für beide Formen, obwohl die korrekte Kommaform im Allgemeinen viel häufiger vorkommt.
Wie in dem oben verlinkten Wikipedia-Artikel erwähnt, gab es bis Mitte/Ende der 2000er Jahre einen großen Mangel an Unterstützung für die richtigen rumänischen Buchstaben. Als ich daran arbeitete, ş/ș und ţ/ț für die Suche zusammenzuführen, stellte ich fest, dass die rumänische Stoppwortliste und der rumänische Stemmer nur die älteren, falschen Cedilla-Formen der Wörter verwendeten! Diese Komponenten stammen aus der schlechten alten Zeit†† (typografisch gesehen) und wurden seitdem nicht mehr aktualisiert.
Als ich die Kommaformen zur Stoppwortliste hinzufügte, wurden 1,4 % der Wörter aus meiner Wiktionary-Stichprobe und 3,4 % der Wörter aus meiner Wikipedia-Stichprobe ausgeschlossen – in beiden Fällen war die große Mehrheit der einzelnen Wörter și (was „und“ bedeutet). Wenn du și zu einem Stoppwort machst, verbessert sich sowohl die Anzahl der Ergebnisse (es ist nicht mehr erforderlich, um einen Treffer zu erhalten) als auch die Rangfolge dieser Ergebnisse (es wird nicht mehr berücksichtigt, wenn es einen Treffer gibt). Wenn du zum Beispiel nach Bosnien și Herțegovina suchst, werden (und sollten) Treffer mit Bosnien und Herțegovina viel stärker gewichtet werden als Treffer mit și.
Es gibt auch einige rumänische Beugungen, die ș und ț verwenden. Etwa 0,9 % der Wörter in meiner Wiktionary-Stichprobe und 1,8 % der Wörter in meiner Wikipedia-Stichprobe wurden nicht korrekt gestammt, werden es aber jetzt.
Unsere Probleme mit den rumänischen Kommas und Cedillen sind gelöst, aber ich habe auch Tickets dafür geöffnet, dass die Stoppwortliste in Lucene und der Snowball Stemmer das Richtige tun – nämlich sowohl ş/ș als auch ţ/ț einbeziehen, da sie alle noch in Gebrauch sind und man leicht übersieht, wenn man das falsche Wort hat.
❦ Bengali/Bangla – Unreine Normalisierung, geschüttelt und gerüttelt
Als ich die Liste der Sprachanalysatoren erstellte, die ausgepackt werden mussten, stellte ich fest, dass unsere damals neue Version von Elasticsearch zwei zusätzliche Analysatoren hatte, die wir nicht aktiviert hatten: Bengalisch und Estnisch. Da sie ausgepackt werden mussten, als sie aktiviert wurden, fügte ich sie meiner Liste der zu bearbeitenden Analyzer hinzu. Die Aktivierung eines neuen Analyzers – vor allem mit einem guten Stemmer, siehe Fußnote ** (in den Fußnoten steht wirklich viel Gutes!) – ist der beste Weg, um einen großen Einfluss auf die Suche nach einer bestimmten Sprache zu haben, also war das eine spannende Aussicht!
Viele der Analyseprogramme, die für die On-Wiki-Suche eingesetzt werden, sind schon lange im Einsatz, schon vor meiner Zeit bei der Foundation, und wurden daher meines Wissens noch nicht explizit getestet oder analysiert. Deshalb werde ich (gerne, wenn auch unerwartet) abgelenkt, wenn ich etwas finde, das nicht stimmt, wie bei Türkisch und Rumänisch oben. Deshalb prüfe ich neue Analysatoren gerne kurz, um sicherzustellen, dass sie nichts tun, was sie offensichtlich nicht tun sollten. Im Laufe der Jahre habe ich schon einige seltsame Dinge gefunden.‡‡
Ich habe eine ganze Reihe von bengalischen Wortgruppen gefunden, die denselben Wortstamm haben, aber keine gemeinsamen Anfangs- oder Endbuchstaben aufweisen – ein Grund für besondere Aufmerksamkeit, aber nicht unbedingt ein Fehler. Die häufigste Variante waren die Anfangsbuchstaben শ, ষ, স (shô, ṣô, sô). Mit Hilfe von Wiktionary und Google Translate sahen die Dinge ziemlich verdächtig aus, aber keines von beiden ist 100% zuverlässig (vor allem in einem Schriftsystem, das ich nicht kenne). Nachdem ich mich mit einigen Bangla-Sprechern beraten und mir einige eindeutig schlechte Beispiele angeschaut hatte – wie বিশ (die Zahl „20“); বিষ („Gift“); বিস („Lotusstängel“), die überhaupt nichts miteinander zu tun zu haben scheinen – beschloss ich, die Quelle der Verwechslung im Bengali-Analysator aufzuspüren.
Der Standard-Bengali-Analysator von Elasticsearch verfügt über einige zusätzliche Komponenten, die über den üblichen Tokenizer, die Kleinschreibung, den Stoppwortfilter und den Stemmer hinausgehen. Es gibt drei Komponenten, die eine zusätzliche Normalisierung vornehmen:
- decimal_digit, das viele nicht-westliche arabische Ziffern (siehe Beispiele unten) in westliche arabische Ziffern (0-9) umwandelt; es wird in Analyzern für sechs verschiedene Sprachen verwendet und scheint eine numerenspezifische Teilmenge von ICU Folding zu sein
- indic_normalization, das „die Unicode-Darstellung von Text in indischen Sprachen normalisiert“ und auch im Hindi-Analyzer verwendet wird
- bengali_normalizer, die spezifisch für Bengali ist, und „den Bengali-spezifischen Algorithmus implementiert, der in: Eine doppelte Metaphon-Kodierung für Bangla und ihre Anwendung in der Rechtschreibprüfung spezifiziert ist“

Der Titel der Arbeit ließ bei mir sofort die Alarmglocken läuten, denn Metaphone und Double Metaphone sind bekannte phonetische Algorithmen. Phonetische Algorithmen dienen dazu, ein Wort auf der Grundlage seiner Aussprache zu kodieren.§§ Ich habe den Algorithmus in der Veröffentlichung mit der Datenanalystin unseres Teams, Aisha Khatun, die zufällig auch Bangla spricht, besprochen. Sie sagte, dass keine der Regeln auf alle Wörter oder sogar die meisten Wörter (für die Suchindexierung) angewendet werden sollte, weil sie auf dem Klang der Buchstaben basieren. Das klingt wie ein hervorragender Algorithmus, um Vorschläge für die Rechtschreibprüfung zu machen – und in der Tat lautet der erste Satz des Abstracts: „Wir stellen eine Double Metaphone Codierung für Bangla vor, die von Rechtschreibprüfprogrammen verwendet werden kann, um die Qualität der Vorschläge für falsch geschriebene Wörter zu verbessern“ – aber das ist kein guter Algorithmus, um Suchbegriffe zu finden.
Ich habe den bengali_normalizer als Teil des Entpackens deaktiviert.
Der Effekt der Einführung eines neuen Analysators – vor allem des Stemmers – war enorm! Die bengalische Wikipedia hatte eine sehr hohe Null-Ergebnis-Rate (49,0 %), und der neue Analyzer lieferte Ergebnisse für etwa ⅐ der Null-Ergebnisse, was die Null-Ergebnis-Rate auf 42,3 % senkte – was immer noch ziemlich hoch ist, aber definitiv besser. Die Gesamtzahl der Abfragen ohne Null-Ergebnisse, die direkt nach der Einführung des Analysators mehr Ergebnisse lieferten, lag bei 33,0 % – ⅓ der Abfragen lieferten also auch mehr Ergebnisse!
❦ Arabisch, Arabisch, & Arabisch – Ressourcen nutzen, Erfolg teilen
Als ich den Arabisch-Analysator auspackte, bat ich Mike Raish vom WMF Design Research Team, mir dabei zu helfen, sicherzustellen, dass alle arabischen Zeichen, die von ICU Folding verändert wurden, in einem arabischsprachigen Kontext angemessen sind. Es war tatsächlich alles in Ordnung!
Als ich daran arbeitete, die Änderungen für Arabisch (Sprachcode ar) auszupacken, bemerkte ich einige Wikis mit den Sprachcodes ary und arz – die sich als die Codes für marokkanisches Arabisch und ägyptisches Arabisch herausstellten. Ich habe ein wenig recherchiert und herausgefunden, dass es zumindest plausibel ist, dass der Analysator für Standardarabisch – oder zumindest einige seiner Komponenten – auch für die anderen arabischen Varianten funktionieren könnte.‖‖
Mike half mir dabei, die Stoppwort- und Stemmer-Komponenten für den Einsatz in diesen beiden Wikis zu überarbeiten, und sie funktionierten gut. Wir haben die Stoppwortliste stark erweitert und zusätzliche orthografische Varianten und Wörter mit Präfixen aufgenommen.
Als die Änderungen eingeführt wurden, gab es enorme Verbesserungen bei der Null-Ergebnis-Rate! Etwa 1 von 5 Abfragen auf der marokkanisch-arabischen Wikipedia (von 55,3 % auf 44,8 %) führt jetzt zu Ergebnissen, und mehr als 1 von 3 Abfragen auf der ägyptisch-arabischen Wikipedia (von 54,5 % auf 34,2 %) führt jetzt zu Ergebnissen! Ein ähnlicher Anteil aller Suchanfragen liefert ebenfalls mehr Ergebnisse – 1 von 5 für die marokkanisch-arabische Wikipedia und 1 von 3 für die ägyptisch-arabische Wikipedia.
❦ Falti McFalterson und Freunde
Wie bereits erwähnt, hätte das Entpacken von Analysatoren, damit sie jeweils der entsprechenden Standardkonfiguration des gebündelten Analysators entsprechen, keine Auswirkungen auf die Ausgabe des Analysators – es sind dieselben Prozesse, die nur explizit statt implizit angegeben werden. Unsere Standard-Upgrades – ICU-Normalisierung, ICU-Faltung und Homoglyphenbehandlung – können jedoch zu Verbesserungen bei der Null-Ergebnisrate und der Anzahl der zurückgegebenen Ergebnisse führen.¶¶
Den größten Einfluss hat die ICU-Faltung in der Regel durch das Ignorieren fremder diakritischer Zeichen. Zum Beispiel würde die Suche nach Muju Dogyo in der englischen Wikipedia ohne ICU Folding null Ergebnisse liefern. Mit ICU Folding findet sie Mujū Dōgyō und erhält (derzeit) zwei Ergebnisse. Das Eintippen von ū und ō ist auf den meisten europäischsprachigen Tastaturen schwierig, weil die Buchstaben außerhalb des romanisierten Japanisch oder einer technischen Anwendung nicht häufig verwendet werden. Gebräuchlichere japanische Wörter und Begriffe wie rōmaji und nattō kommen häufiger vor, vor allem in relevanteren Artikeln – und die stets hilfreichen WikiGnomes haben Weiterleitungen von den diakritiklosen Versionen an die richtige Stelle erstellt;## so dass ICU Folding in diesen Fällen nicht viel hilft, obwohl es auch nicht schadet.
In manchen Fällen stellt sich jedoch heraus, dass diakritische Zeichen, die in der offiziellen Schreibweise einer Sprache verwendet werden, in der Umgangssprache nicht so gebräuchlich sind – vor allem, wenn die Buchstaben mit diakritischen Zeichen nicht als eigenständige Buchstaben betrachtet werden. Im Schwedischen zum Beispiel ist å ein anderer Buchstabe als a. Vermutlich sind sie aber offensichtlich verwandt – aber warte noch ein paar tausend Jahre: Die meisten Menschen scheinen vergessen zu haben, dass G ursprünglich eine Variante von C war. Vergleiche das Spanische, wo á ein a mit einem Akzent ist, aber immer noch ein a.
Wiki-Inhalte sind in der Regel förmlicher verfasst, aber die Abfragen können ganz schön durcheinander sein. Es scheint besonders häufig vorzukommen, dass Leute diakritische Zeichen weglassen, die technisch von ihrer Rechtschreibung verlangt werden, die aber in der Praxis in bestimmten Wörtern oder allgemeinen Mustern vorkommen, die so gebräuchlich sind, dass niemand durch das Fehlen der diakritischen Zeichen verwirrt wird. Einige Beispiele:
- Akut gesetzte Akzente im Spanischen deuten oft auf eine unvorhersehbare Betonung hin, aber selbst als mittelmäßiger Spanisch-Sprecher habe ich nie in Frage gestellt, wo die Betonung in Jose Gomez de Peru (vielleicht formeller bekannt als José Gómez de Perú) liegt; spanische Suchende schreiben sie nicht immer
- Irische Suchende sind sich einig, dass einige Namen, wie Seamus Padraig O Suilleabhain, keine Akzente brauchen, um klar zu sein, obwohl die WikiStickler ihn fast immer formeller als Séamus Pádraig Ó Súilleabháin schreiben
- Portugiesische Suchende machen sich nicht immer die Mühe, Tilden zu schreiben, besonders bei são (oft „Heiliger“, häufig in Ortsnamen wie São Paulo verwendet).
- Katalanische Suchende mögen es nicht, den Akzent in -ció (das mit dem spanischen -ción und dem englischen -tion verwandt ist) zu schreiben; auch galicische Suchende schreiben häufig -cion für -ción
- Technisch gesehen braucht es den Akzent, um die Betonungsregeln zu befolgen, aber es ist eine so gebräuchliche Endung, dass niemand sie mit etwas anderem verwechseln wird, wenn sie nicht akzentfrei ist, genauso wie ein englischer Sprecher -tion nie als „ti-on“ aussprechen wird.
- Es überrascht nicht, dass baskische Suchende ziemlich häufig nach spanischen Wörtern suchen, aber es überrascht auch nicht, dass sie nicht immer die Akzente tippen
❦ Hindi – Translitierte Texte & Tastaturspielereien
Leider hatten weder ICU Folding noch die anderen allgemeinen Verbesserungen einen großen Einfluss auf die Hindi-Wikipedia-Abfragen. In einigen anderen Sprachen war der Einfluss ähnlich gering. Das kommt vor.
Was bei den Hindi-Daten auffiel, war die unglaublich hohe Null-Ergebnis-Rate, mit oder ohne ICU Folding. Die typische Null-Ergebnis-Rate für eine große Wikipedia liegt bei 25 % bis 35 %.◊◊ In Hindi waren es über 60 %! Da ich eine vernünftige Stichprobe von Abfragen vor mir hatte, beschloss ich, nachzuschauen, ob ich einen offensichtlichen Grund dafür finden konnte, dass etwas seltsam schief gelaufen sein könnte.
Fast 85 % der Null-Ergebnisse bei der Hindi-Wikipedia sind in lateinischer Schrift, und fast 70 % davon sehen offensichtlich wie Hindi aus, wenn sie aus Devanagari transliteriert werden, und etwa 40 % davon liefern Ergebnisse, wenn sie zurück transliteriert werden (ich habe Google Translate benutzt, um das zu testen). Grob geschätzt könnten also fast ¼ der Abfragen in der Hindi-Wikipedia, die keine Null-Ergebnisse liefern, mit einer vernünftigen Latein-Devanagari-Transkription wiederhergestellt werden! (Das steht auf der Liste unserer zukünftigen Projekte.)
❦ Über Thai und Tokenisierung
Die thailändische Sprache wird in der Regel ohne Leerzeichen zwischen den Wörtern geschrieben, so dass die Tokenisierung – das Zerlegen in Wörter – eine Herausforderung ist. Von den standardmäßig in Elasticsearch enthaltenen Analyseprogrammen ist Thai das einzige, das nicht den Standard-Tokenizer verwendet,☞☞ sondern einen eigenen Thai-Tokenizer. Der thailändische Tokenizer verwendet vermutlich ein Wörterbuch und einige Heuristiken, um Wortgrenzen im thailändischen Text zu finden.
Bei meiner Analyse habe ich festgestellt, dass der Thai-Tokenizer einige nicht-thailändische Dinge anders macht als der Standard-Tokenizer. Er lässt Token mit doppelten Anführungszeichen zu (z. B. den Tippfehler let”s); außerdem erlaubt er Bindestriche,*** en-Bindestriche, em-Bindestriche, horizontale Balken, Bindestrich-Minus in voller Breite, Prozentzeichen und Ampersands. Der Standard-Tokenizer trennt Wörter an all diesen Zeichen.
Noch wichtiger ist jedoch, dass der thailändische Tokenizer durch Leerzeichen mit Null-Breite verwirrt werden kann, die in thailändischen Texten relativ häufig vorkommen (zumindest in unseren Wikis). Der Tokenizer scheint in einen Zustand zu geraten, in dem er nicht mehr parst, bis er auf ein Leerzeichen oder ein anderes Zeichen stößt, das eindeutig eine Wortgrenze darstellt. Das Ergebnis können sehr lange Token sein. Das längste war über 200 Zeichen lang! (Ohne die Leerzeichen wurden 49 Wörter geparst, von denen 20 als Stoppwörter gelöscht wurden).

Es gibt zwei veraltete Thai-Zeichen, ฃ und ฅ, die im Allgemeinen durch die ähnlich aussehenden und ähnlich klingenden ข und ค ersetzt wurden. Diese veralteten Zeichen verwirren auch den thailändischen Tokenizer und führen dazu, dass er sehr lange Token erzeugt.
Die thailändische Schrift ist von der alten Khmer-Schrift abgeleitet und hat deshalb auch einige der Probleme, die das moderne Khmer bei der Anordnung der Zeichen und der Glyphenbildung hat – zum Glück in viel geringerem Umfang! (Einen Moment lang habe ich mir wirklich Sorgen gemacht, denn ich habe viel Zeit damit verbracht, die häufigsten Probleme mit der Sortierung in Khmer zu lösen).
Hier sind zum Beispiel vier Zeichenfolgen, die gleich aussehen können, und wie oft sie zum Zeitpunkt meiner Untersuchung in der thailändischen Wikipedia auftauchten:
- กล่ำ = ก + ล + ่ + ำ (8900 Vorkommen)
- กลํ่า = ก + ล + ํ + ่ + า (80 Vorkommen)
- กล่ํา = ก + ล + ่ + ํ + า (6 Vorkommen)
- กลำ่ = ก + ล + ำ + ่ (2 Vorkommen)
Da die Darstellung von Glyphen je nach Schriftart, Betriebssystem und Browser sehr unterschiedlich ausfallen kann, findest du unten einen Screenshot der gleichen Zeichen wie oben, dargestellt auf einem MacBook in den Schriftarten Helvetica, Microsoft Sans Serif und Sathu (und in Everson Mono auf der linken Seite für die Aufschlüsselung nach Zeichen).

Die zwei häufigsten Versionen des Wortes werden in mehr als einem Dutzend Schriftarten, die ich getestet habe, gleich dargestellt. Die dritte Variante wird oft gleich wiedergegeben, wie in Sathu, aber manchmal auch anders, wie in Microsoft Sans Serif (beachte, dass die Diakritika vertauscht sind), und manchmal gebrochen, wie in Helvetica. Die vierte wird selten gleich wiedergegeben wie die anderen, aber in Sathu schon. Oft wird sie anders wiedergegeben, wie in Microsoft Sans Serif, und manchmal gebrochen, wie in Helvetica. (Beachte, dass die gebrochene Darstellung in Helvetica wohl die korrekteste ist, weil die diakritischen Zeichen nicht in der „richtigen“ Reihenfolge gemäß dem Unicode-Standard verwendet werden).
All diese Variationen – wie bei Khmer (wo noch viel mehr los ist!) – sind schlecht für die Suche, weil Wörter, die gleich aussehen, in Wirklichkeit anders geschrieben werden. Im Englischen ist das so, als ob c+l+a+y, c+a+l+y und c+l+y+a im Druck alle wie clay aussehen. Und natürlich können diese nicht kanonisch geordneten Zeichen den thailändischen Tokenizer verwirren – weil nicht jede Variante in seinem Wörterbuch steht – und dazu führen, dass er mehr dieser wirklich langen Token erzeugt.
Es wäre nicht so schlimm, wenn der thailändische Tokenisierer veraltete Zeichen oder falsch angeordnete diakritische Zeichen überspringen könnte – schließlich sind sie im Grunde genommen Tippfehler – und auf der anderen Seite mit dem Heraussuchen von Wörtern beginnen würde; die Tatsache, dass er einfach aufgibt und alles in der Nähe als ein einziges langes Token behandelt, ist so schlimm.
Auftritt des ICU Tokenizers! Die ICU Unicode-Komponenten umfassen nicht nur die ICU-Normalisierung und die ICU-Faltung – es gibt auch einen ICU-Tokenizer. Er verfügt über Wörterbücher und/oder Heuristiken für eine ganze Reihe von Leerzeichen-losen ostasiatischen Sprachen, darunter Thai, Chinesisch, Japanisch, Koreanisch, Khmer, Laotisch und andere, so dass er diese Sprachen in einem einzigen Paket parsen kann.
Beim Vergleich der beiden Tokenizer habe ich ein paar neue Dinge entdeckt:
- Der thailändische Tokenizer behandelt einige Symbole und Emojis sowie Ahom (𑜒𑜑𑜪𑜨) und Grantha (𑌗𑍍𑌰𑌨𑍍𑌥) im Wesentlichen wie Satzzeichen und ignoriert sie vollständig; außerdem ignoriert er inkonsistent einige New Tai Lue (ᦟᦲᧅᦷᦎᦺᦑᦟᦹᧉ) Token.
- Der Thai-Tokenizer zerlegt wirklich lange Textzeilen in 1024-Zeichen-Stücke, selbst wenn dabei ein Wort in zwei Hälften geteilt wird!
- Der ICU-Tokenizer trennt keine thailändischen oder arabischen Zahlen von benachbarten thailändischen Wörtern. Das ist in Sprachen sinnvoll, in denen die Wörter Leerzeichen haben und die Zahlen wahrscheinlich absichtlich an die Wörter angehängt werden – so ist 3a wirklich 3a und nicht 3 + a -, aber in Thai ist es weniger sinnvoll.
Der ICU-Tokenizer scheint tatsächlich besser für Thai-Text geeignet zu sein als der Thai-Tokenizer, und seine vergleichbaren Mängel (z.B. #3 oben) können mit ein paar Ergänzungen zum ungepackten Thai-Analyzer behoben werden, um strategisch Leerzeichen an den richtigen Stellen hinzuzufügen.
Der ICU-Tokenizer hat jedoch einige weitere bekannte Probleme. Das ärgerlichste für mich – da Homoglyphen meine persönliche Nemesis sind – ist, dass er Token mit gemischter Schrift auflöst, so dass unser Freind chocоlate – bei dem das fette Zeichen in der Mitte kyrillisch ist – in drei Token aufgeteilt wird: choc, о, late. Auf diese Weise aufgespalten, können sie von unseren Upgrades zur Behandlung von Homoglyphen nicht mehr repariert werden. (Außerdem werden nicht-homoglyphische, gemischte Zeichen wie KoЯn in Ko + Я + n zerlegt).
Noch falscher ist wohl, dass der ICU-Tokenizer in bestimmten Kontexten auch einige seltsame Dinge mit Token macht, die mit Zahlen beginnen. So wird zum Beispiel x 3a als x + 3a geparst (weil x und a beides lateinische Zeichen sind), während ร 3a als ร + 3 + a geparst wird (weil ร und a nicht im selben Zeichensatz sind – ja, das ist seltsam).
Nachdem ich den ICU-Tokenizer aktiviert und einige zusätzliche Schritte hinzugefügt hatte, um Leerzeichen zu entfernen, veraltete Zeichen zu ersetzen und diakritische Zeichen neu zu ordnen, hatte meine thailändische Wiktionary-Probe 21 % mehr Token und meine thailändische Wikipedia-Probe 4 % mehr Token. Auch die Zahl der eindeutigen Token ist drastisch gesunken – um etwa 60 %. Auch die durchschnittliche Länge der unterscheidbaren thailändischen Wörter sank: von 7,6 auf 5,1 in der Wikipedia-Stichprobe. All dies deutet darauf hin, dass längere Phrasen in einzelne Wörter zerlegt werden, von denen die meisten an anderer Stelle im Text vorkommen. Im Englischen wäre myThaiWiktionarysample ein einziges, längeres Token, während my + Thai + Wiktionary + sample vier kürzere Token ergibt, die alle an anderer Stelle vorkommen.
Als ich mir die Auswirkungen des ICU-Tokenizers nach dem Einsatz ansah, entdeckte ich, dass der Thai-Tokenizer nicht nur lächerlich lange Token erzeugt, sondern manchmal auch lächerlich kurze Token, die den Text in einzelne Thai-Zeichen zerlegen. Das kann zu vielen falsch positiven Übereinstimmungen führen. Zum Vergleich: Das Wort Thai findet man nur in einem kleinen Teil der Artikel in der englischen Wikipedia, aber wenn wir einzelne Buchstaben indizieren würden, dann würde die Suche nach t, h, a und i fast jeden Artikel im Wiki finden!
Zum ersten (und bisher einzigen) Mal stieg also die Null-Ergebnis-Rate nach dem Auspacken, Aktualisieren und Modifizieren eines Analyzers um 1,5 % an, was auf die Auswirkungen des ICU-Tokenizers zurückzuführen ist. Bei etwa 0,5 % der Abfragen wurden aus null Ergebnissen einige Ergebnisse – vor allem, weil wirklich lange Token aufgelöst wurden – und bei etwa 2 % der Abfragen wurden aus einigen Ergebnissen null Ergebnisse – vor allem, weil die Wörter nicht mehr in einzelne Buchstaben aufgelöst wurden.
❦ Irisch – Gepunktete Punkte & Überpunkte
Ältere Formen der irischen Rechtschreibung verwenden einen Überpunkt (ḃ, ċ, ḋ, etc.), um eine Verlängerung anzuzeigen, die jetzt normalerweise mit einem folgenden h (bh, ch, dh, etc.) angezeigt wird.††† Es war einfach genug, die Zuordnung (ḃ → bh, etc.) zum ungepackten irischen Analysator hinzuzufügen. Da diese Zeichen nicht so häufig vorkommen, gab es nicht viele Änderungen, aber eine Handvoll neuer guter Übereinstimmungen.
Eine weitere Besonderheit der gälischen Schrift ist, dass das klein geschriebene i ohne Punkt ist (ı). Da es im Irischen jedoch keinen Unterschied zwischen i und ı gibt, wird i in der Regel im Druck und in elektronischen Texten verwendet. ICU Folding wandelt ı bereits in i um.
Das irische Wort amhráin („Lieder“) kam in meinem Beispielkorpus sowohl in seiner modernen Form als auch in seiner älteren Form, aṁráın (mit punktiertem ṁ und punktlosem ı), vor. Durch das Hinzufügen des Overdot-Mappings plus und der ICU-Faltung können diese beiden Formen übereinstimmen!
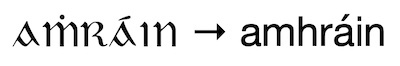
Die Zukunft – Leben in Harmonie
Das Auspacken aller monolithischen Sprachanalysatoren ist lediglich ein Schritt – aber bei weitem der größte Schritt – in einem größeren Plan, die Sprachanalyse in allen Sprachen und Wikis zu harmonisieren. Das bedeutet natürlich nicht, dass sie alle identisch sein sollen.¶¶¶ Es wird immer eine sprachspezifische Verarbeitung in einigen Wikis geben – wir lieben die sprachspezifische Verarbeitung, ich wünschte, wir könnten sie für mehr Wikis machen!### Und natürlich ist es sinnvoll, sich auf die Seite der „Muttersprache“ eines Wikis zu schlagen und den Text so zu verarbeiten, wie es für diese Sprache am besten funktioniert.
Was keinen Sinn macht, ist, dass Mr. Rogers, Mr_Rogers und MrRogers in verschiedenen Wikis unterschiedlich behandelt werden, bevor eine sprachspezifische Verarbeitung stattfindet, und dass sie an verschiedenen Stellen mit Mr. Rogers übereinstimmen können oder auch nicht. Oder dass D’Artagnan in einigen Wikis mit D’Artagnan übereinstimmt, in anderen aber nicht. Oder dass chocоlate – bei dem das verdammte fette Zeichen in der Mitte immer noch kyrillisch ist – in einem Wiki mit normaler chocolate (deutsch: Schokolade) übereinstimmt, in einem anderen aber mit lateоchocΔΔΔ in gemischter Schreibweise.
Alle nicht sprachspezifischen Verarbeitungen in den verschiedenen Wikis sollten so weit wie möglich übereinstimmen, wobei Abweichungen durch sprachspezifische Belange begründet sein sollten und nicht durch historische Zufälle bei der Entwicklung und dem Einsatz der Analysatoren. Und wenn die Sprachanalysatoren erst einmal so harmonisch wie möglich sind, wird es einfacher◊◊◊ sein, Verbesserungen in allen Sprachen vorzunehmen.↓↓↓
Coda – Anmerkungen und Fußnoten
Wenn du nach diesem lächerlich langen Blog-Beitrag noch nicht genug hast, solltest du dir professionelle Hilfe suchen kannst du dir jederzeit meine Notizen-Seiten auf MediaWiki ansehen. Ich habe eine noch lächerlich längere Seite mit all meinen Auspacknotizen, die weniger Hintergrund, aber mehr technische Details enthält. Ich dokumentiere die meisten meiner sprach- und suchbezogenen Projekte auf MediaWiki, mit Links auf meine Hauptnotizen-Seite.
Bevor ich gehe, hoffe ich, dass dir das Lesen der Fußnoten nur halb so viel Spaß gemacht hat wie mir das Schreiben. Du hast doch die Fußnoten gelesen, oder?☞☞☞
* Was ist ein/e Computerlinguist/in, fragst du? Die Details variieren von Computerlinguist/in zu Computerlinguist/in,† aber in meinem Fall lautet die kurze Antwort: „eine Spezialisierung des/der Softwareingenieur/in“. Aufmerksamen Leser/innen meiner früheren Blogs wird aufgefallen sein, dass in meinen früheren Beiträgen „Software-Ingenieur/in“ und nicht „Computerlinguist/in“ stand. Beides ist richtig, aber „Computerlinguist/in“ ist spezifischer.
† Das, was passiert, wenn du ein Wort immer wieder hörst oder siehst und es seine Bedeutung verliert, nennt man semantische Sättigung. Computerlinguist, Computerlinguist, Computerlinguist.
‡ Wahrscheinlich darf ich keinen Favoriten haben – aber eines der am schlechtesten gehüteten Geheimnisse der Welt ist, dass Wiktionary mein Favorit ist. Sag es nicht den anderen Projekten.
§ Die genaue Anzahl kann sich immer wieder ändern, weil immer wieder neue Analysatoren hinzukommen, aber es ist auch einfach schwer, die vorhandenen „Sprachen“ zu zählen. Es gibt Analyzer für Portugiesisch und „Brasilianisch“ (auch bekannt als Portugiesisch), die sich nicht so sehr unterscheiden – zwei Analyzer, eine Sprache. Und es gibt den CJK Analyzer, der Chinesisch, Japanisch und Koreanisch unterstützt – drei Sprachen, ein Analyzer – obwohl wir ihn im Moment nur für Japanisch verwenden.
‖ Die meisten Sprachen verwenden einen Standard-Tokenizer, um Wörter zu finden, aber Thai hat seinen eigenen Tokenizer. Der CJK-Analysator versucht gar nicht erst, chinesische, japanische oder koreanische Wörter zu finden; er zerlegt CJK-Text einfach in sich überschneidende Bigramme. Sprachen mit Schriftsystemen ohne Groß- und Kleinschreibung wie Arabisch, Bengalisch oder Chinesisch haben immer noch einen Schritt zur Kleinschreibung, um mit Fremdwörtern umzugehen, denn Englisch ist wie ein bad penny – es taucht überall auf. Eine Handvoll Analysatoren – Persisch, Thailändisch und CJK – enthalten keine Stemmer.
¶ Und wahrscheinlich ist es auch nicht so einfach. Nichts ist das jemals.
# Eine lustige Herausforderung für Wort-Nerds: Kannst du ein Dutzend Schriftsysteme nennen? Zwei Dutzend? Vier Dutzend? Oder sogar 50! (Tipp: Allein mit den brahmischen Schriften schaffst du ⅔ davon, und hier ist ein Spickzettel, mit dem du auf über 100 kommst).
Δ Es wäre auch toll, wenn Hawai’i und Hawaiʻi mit Hawai′i, Hawai´i, Hawai῾i, Hawai‛i und Hawai`i übereinstimmen würden, die alle in der englischen Wikipedia vorkommen, aber so weit sind wir noch nicht. Hawai*i, Hawai,i und Hawai«i kommen auch in der englischen Wikipedia vor, aber ich habe kein schlechtes Gewissen, dass ich sie nicht gefunden habe. Falls du neugierig bist: Die apostrophähnlichen Zeichen sind in der Reihenfolge ihres Auftretens: Apostroph (‘), Hawaiʻian okina, auch bekannt als „Komma als Modifizierungsbuchstabe“ (ʻ), rechtes geschweiftes Anführungszeichen (’), linkes geschweiftes Anführungszeichen (‘), Apostroph als Modifizierungsbuchstabe (ʼ), Primzahl als Modifizierungsbuchstabe (ʹ), Primzahl (′), Akutakzent (´), griechische Dasia (῾), Anführungszeichen als umgekehrtes Komma (‛) und Gravisakzent (`). In der Rubrik „Was zum…?“ gibt es außerdem Sternchen (*), Komma (,) und linkes Gillemet («).
◊ Eine kleine Softwareentwickler-Weisheit: Es gibt keine garantierte „schnelle, einfache Lösung“. Viele einfache Lösungen sind in der Tat schnell, aber es gibt immer irgendeinen Blödsinn, der passieren könnte. Es gibt einen Grund, warum es die 90-90-Regel gibt!
↓ Ausnahmsweise kamen die großen Weltsprachen zu kurz und nicht die kleineren, meist weniger gut unterstützten Sprachen. Unsere Standardverbesserungen, wie die Behandlung von Homoglyphen und die ICU-Normalisierung (aber nicht die aggressivere ICU-Faltung), sind standardmäßig für alle Sprachen/Wikis aktiviert, die keinen monolithischen Sprachanalysator haben.
☞ „Erfahrung ist das, was du bekommst, wenn du es brauchst.“ Jedes Mal, wenn ich etwas Seltsames oder Unerwartetes bei einer Sprache oder einem Analyzer entdecke, aktualisiere ich meine Skripte, um dieses potenzielle Problem in Zukunft hervorzuheben, damit ich mich nicht noch einmal mit genau demselben Problem herumschlagen muss.
** Bei der Suche ist eine Verbesserung von 1 % bei jeder Standardmessung – Abruf, Genauigkeit, Null-Ergebnis-Rate usw. – eine ziemlich große Sache. Die Suche ist in der Regel sehr gut, und normalerweise arbeiten wir nur an den Rändern, um sie zu verbessern. Die Ausnahme von dieser Regel ist im Bereich der Sprachanalyse das Hinzufügen eines Stemmer, wo es vorher keinen gab. Im Englischen gibt es im Allgemeinen nicht viel grammatikalische Flexion – dog/dogs und hope/hopes/hoped/hoping sind so ziemlich alles! Das Beste/Schlechteste, was das Englische zu bieten hat, ist wahrscheinlich das höchst unregelmäßige be, mit gerade mal acht Formen: be, being, been, am, is, are, was, were. In den romanischen Sprachen kann jedes Verb etwa 50 Konjugationen haben (z. B. französisch: manger, 48; italienisch: mangiàre, 58; spanisch: comer, 68), und im Finnischen mit seinem umfangreichen Kasussystem können Substantive Tausende von Formen haben, auch wenn die meisten nur selten verwendet werden. Wenn du all diese Formen mit einem Stemmer zusammenführst, kannst du die Anzahl der Ergebnisse für viele Suchanfragen erheblich verbessern.
†† Regelbasierte Stemmer sind relativ leicht und billig und es gibt sie schon ewig. Sie enthalten zwar keine umfangreichen Ausnahmelisten (wie z.B. Niederländisch/Holland oder be/been/being/am/is/are/was/were), aber sie können für viele Sprachen eine große Hilfe sein.
‡‡ Ein paar Beispiele: Ein Analysator hat alle Satzzeichen in Kommas umgewandelt und sie indiziert. (Satzzeichen werden normalerweise bei der Indizierung verworfen.) Das Ergebnis war, dass alle Satzzeichen in einer Abfrage mit allen Satzzeichen im gesamten Wiki übereinstimmten. Ein anderer Stemmer übersetzte kyrillisch in lateinisch, da die Sprache beides verwendete, aber aufgrund der Art und Weise, wie der Code geschrieben war, verwarf er versehentlich jeden Text, der nicht lateinisch oder kyrillisch war, anstatt ihn unverändert durchzulassen. Ein anderer statistischer Stemmer hatte ein Problem mit Fremdwörtern und Zahlen und verwechselte am Ende Hunderte von zufälligen Wörtern und Namen miteinander. All diese Probleme konnten mit verschiedenen Patches am Code oder an der Konfiguration größtenteils oder vollständig behoben werden.
§§ Phonetische Algorithmen werden in der Rechtschreibprüfung eingesetzt – zum Beispiel, um Menschen dabei zu helfen, Genealogie richtig zu schreiben – und in der Genealogie, um ähnlich klingende Namen zusammenzufassen – zum Beispiel, um die vielen Schreibweisen von Caitlin zu finden… obwohl nur wenige eine Chance haben, KVIIIlyn zu finden – aber ich schweife ab.
‖‖ Anhand der Namen von Sprachen kann man nie sagen, wie eng sie miteinander verwandt sind. Es gibt einen alten Witz, der besagt, dass „eine Sprache ein Dialekt mit einer Armee und einer Marine ist“ – die Unterscheidung zwischen eng verwandten „Sprachen“ ist oft sozial oder politisch. Die so genannten „Dialekte“ des Chinesischen sind ungefähr so unterschiedlich wie die romanischen Sprachen, während Bosnisch, Kroatisch und Serbisch ungefähr so unterschiedlich sind wie einige Dialekte des Englischen und im Allgemeinen gegenseitig verständlich sind.
¶¶ Sie können sich auch auf das Ranking auswirken und darauf, welcher spezifische Text für ein bestimmtes Snippet ausgewählt wird, das mit den Ergebnissen auf der Seite Spezial:Suche angezeigt wird. Ich schaue mir in der Regel die Änderungen im obersten Ergebnis an, obwohl das bei weniger häufigen Wörtern und/oder kleineren Wikis aufgrund der Art und Weise, wie die Wortstatistiken berechnet werden, etwas unscharf sein kann. So haben die verschiedenen Suchabschnitte in unserem Suchcluster leicht unterschiedliche Wortstatistiken, je nachdem, welche Dokumente in den einzelnen Abschnitten gespeichert sind. In einigen seltenen Fällen liegen die Ergebnisse der besten Dokumente so nah beieinander, dass winzige Unterschiede in den Wortstatistiken zwischen den Servern, die normalerweise einen Rundungsfehler in der Trefferliste darstellen würden, ausreichen, um die endgültige Reihenfolge der Ergebnisse zu beeinflussen. Wenn du die Seite neu aufrufst, erhältst du möglicherweise Ergebnisse von einem anderen Suchserver, wo diese winzigen Unterschiede dazu führen, dass einige Top-5-Ergebnisse die Plätze tauschen. Das passiert am ehesten bei einem sehr seltenen Suchbegriff, der nur ein- oder zweimal in jedem von nur einem Dutzend oder weniger Dokumenten vorkommt, und zwar nicht im Titel eines dieser Dokumente. Ich schaue mir normalerweise keine anderen Ranking- oder Snippet-Änderungen an, es sei denn, es gibt einen Grund zu der Annahme, dass etwas seltsam schief gelaufen ist.
## Die WikiGnome sind großartig, und wir sollten sie alle mehr schätzen. Wenn ich in einem Blogbeitrag, einem Phabricator-Ticket oder einer E-Mail-Liste ein Beispiel für etwas gebe, das im Wiki nicht richtig funktioniert, wird es oft von einem freundlichen WikiGnome korrigiert, was ich sehr schätze. Eines meiner Lieblingsbeispiele war vor Jahren bei einem völlig anderen Projekt: Wir haben auf Phabricator darüber diskutiert (und geklagt), dass es in der englischen Wikipedia kein offensichtlich gutes Ergebnis für die Suchanfrage „Marineflaggen“ gab, und… um es kurz zu machenΔΔ… Thryduulf hat eine gute Begriffsklärungsseite für „Marineflagge“ erstellt, mit einem Redirect vom Plural und einem Link zu einer neuen Seite „Listen der Marineflaggen“. Jetzt gibt es ein offensichtlich gutes Ergebnis für die Abfrage Marineflaggen!
ΔΔ Was natürlich gegen meine Natur ist.
◊◊ In meiner Anfangszeit bei der Stiftung habe ich mir Sorgen gemacht, dass diese Zahl ziemlich hoch ist – wie viele andere auch. 2015 untersuchte ich die Null-Ergebnis-Abfragen in vielen Wikipedias, um zu sehen, ob es offensichtliche Verbesserungsmöglichkeiten gibt (oder auch nur kleine – siehe Fußnote **). Ich habe einen Fehler in der Wikipedia Mobile App entdeckt, der behoben wurde, aber ich habe auch eine Menge Müll gefunden, der wirklich keine Ergebnisse verdient. Es gibt Bots und Apps, die eine Menge automatisierter Abfragen durchführen. Manchmal sind die Bots mehr als nur ein bisschen willkürlich – böser Programmierer! böse! – aber wir versuchen, uns nicht darum zu kümmern, solange es nicht missbräuchlich wird. Manche Apps scheinen nach etwas Nützlichem zu fischen, das sie ihren Nutzern zeigen können, aber es ist in Ordnung, wenn sie nichts finden. (Und im Allgemeinen ist es immer großartig, dass Menschen auf der kostenlosen Wissensplattform, die wir anbieten, aufbauen!) Programmierer machen einige Fehler, wie z. B. die buchstäbliche Suche nach {searchTerms} anstelle der eigentlichen Suchbegriffe oder die wiederholte Übersäuberung von Daten, so dass “search” (mit geraden Anführungszeichen) am Ende als quot search quot abgefragt wird (wahrscheinlich mit einer Zwischenform wie "search"). Und natürlich machen menschliche Suchende Fehler, indem sie das Falsche in die richtige Suchmaschine einfügen oder vielleicht das Richtige in die falsche Suchmaschine – wir bekommen viele Suchanfragen nach Kauderwelsch oder riesigen Textauszügen (d.h. 1.000-Wort-Anfragen, bevor wir eine Längenbeschränkung eingeführt haben) oder sehr unenzyklopädische Anfragen, die eher für eine allgemeine Web-Suchmaschine geeignet sind (wie Dating-Ratschläge, Pornografie usw.).↓↓
↓↓ Trotzdem gibt es immer noch Leute, die häufig wiederholte Null-Suchanfragen für potenzielle neue Artikel nutzen wollen. Das ist eine gute Idee – das dachte ich auch, als ich sie hatte. Aber in der Praxis gibt es, zumindest in der englischen Wikipedia, nicht wirklich viel davon. Ich habe mir das 2016 angeschaut und eine Menge Pornografie gefunden. Sehr viel Pornografie. Ich glaube, dass die WikiGnome in größeren Wikis schneller arbeiten, als jemand Null-Ergebnisse-Abfragen überprüfen kann, vor allem, wenn neue Weiterleitungen erstellt werden. Außerdem führen viele Suchanfragen, die nicht zum richtigen Ort führen, nicht wirklich zu null Ergebnissen – bei Millionen von Artikeln ist es schwer, nicht etwas zu finden.
☞☞ Der CJK-Analysator erzeugt Bigramme für CJK-Text, was sich deutlich von der Standard-Tokenisierung unterscheidet, aber er verwendet in einem ersten Schritt den Standard-Tokenizer, der eine Menge Nicht-CJK-Text verarbeitet. Ein späterer cjk_bigram-Schritt parst Sequenzen von CJK-Token in überlappende CJK-Bigramme um.
*** Ich habe auch gelernt, dass der übliche Bindestrich, der auch als Minuszeichen fungiert (- U+002D „HYPHEN-MINUS“) und den ich für den Bindestrich hielt, nicht der einzige Bindestrich ist… es gibt auch ‐ (U+2010 „HYPHEN“). Da ich das typische „Bindestrich-Minus“ in meinen Berichten als „Bindestrich“ bezeichnet hatte, brauchte ich eine Weile, um zu erkennen, dass das Zeichen, das nur „Bindestrich“ genannt wird, etwas anderes ist. Lustige Zeiten!
††† Das grenzt an eine orthografische Verschwörungstheorie, aber die Umwandlung von Overdots in –h im Irischen hat mich dazu gebracht, darüber nachzudenken, wie h in mehreren europäischen Sprachen verwendet wird, um anzuzeigen, dass etwas ein verwandter Laut ist, den man nicht anders schreiben kann. Im Englischen ist das häufig der Fall, mit ch, sh, th und zh und manchmal auch mit kh – und vielleicht wh, je nach Akzent – und ph, auch wenn wir einfach nur ein f da stehen haben.‡‡‡ Das Französische verwendet ch und das Deutsche verwendet sch für den Laut, den wir im Englischen als sh schreiben. Polnisch und Ungarisch verwenden auch z als Markierung für „ähnliche Laute“. Andere Digraphen§§§ sind ein bisschen kombinatorischer, zum Beispiel wenn dz mehr oder weniger wie d + z klingt.
‡‡‡ Es gibt etymologische Gründe – vor allem griechische – für viele Fälle von ph statt f, aber die englische Rechtschreibung ist so schrecklich, dass ich mir nicht sicher bin, ob es das wert war.
§§§ Es macht Spaß – und zwar nach der Definition eines Wort-Nerds von Spaß – Digraphen, Trigraphen, Tetragraphen, Pentagraphen und Hexagraphen auf Wikipedia nachzuschlagen. Beachte, dass die meisten Beispiele für Pentagraphen und alle Beispiele für Hexagraphen irisch sind. Die irische Rechtschreibung ist eine der wenigen, die der englischen Rechtschreibung in puncto Furchtbarkeit orthografischer Tiefe in nichts nachsteht.‖‖‖
‖‖‖ [Die Tangente wird wild!] Ein interessanter Fall von asymmetrischer mehrsprachiger orthografischer Tiefe ist die Sprache Santa Cruz, die auch Natügu genannt wird, was auch Natqgu geschrieben wird. Ihre Rechtschreibung ist sehr „flach“, mit einem fest verankerten „ein Buchstabe, ein Laut“-Prinzip. In den 1990er Jahren beschloss man jedoch, die diakritischen Buchstaben, die vor Ort nur schwer zu tippen, zu veröffentlichen oder zu fotokopieren waren, abzuschaffen und durch einfachere Buchstaben zu ersetzen – nämlich die, die auf einer amerikanischen englischen Schreibmaschine geschrieben werden und für nichts anderes verwendet wurden. Deshalb sind c, q, r, x und z in Natqgu Vokale – die Rechtschreibung ist also zwar flach, aber für die meisten anderen Benutzer des lateinischen Alphabets ziemlich undurchsichtig. Siehe „Wenn c, q, r, x und z Vokale sind: Ein informeller Bericht über die Natqgu-Rechtschreibung“ (~400K PDF) für mehr!
¶¶¶ Es wäre so schnell und einfach gewesen, nur einen Analysator für alles zu haben – aber er wäre in allem miserabel gewesen.
### Und ich bin immer auf der Suche nach Möglichkeiten, noch mehr zu tun. Im Laufe der Jahre haben wir Chinesisch, Esperanto, Hebräisch, Khmer, Koreanisch, Mirandesisch, Nias, Polnisch, Serbisch und Kroatisch, Slowakisch und Ukrainisch erweitert und verbessert. Einige davon wurden durch die Verfügbarkeit von Open-Source-Software ermöglicht, andere durch Phabricator-Tickets, die Probleme meldeten, und wieder andere durch motivierte Freiwillige, die die Sprache sprechen. Wenn du eine gute Open-Source-Sprachverarbeitungssoftware kennst – vor allem Stemmer -, die in unseren Tech-Stack integriert werden könnte (ich bin ziemlich geschickt mit dem Hammer!), oder wenn du ein kleines Problem oder eine Aufgabe gefunden hast – die kleiner ist als Stemmer -, die wir möglicherweise lösen könnten, öffne ein Phab-Ticket und schreibe mir ein @. (Der Geist jedes Produktmanagers, mit dem ich je zusammengearbeitet habe, erinnert mich daran, dass ich nicht versprechen kann, dass wir dein Ticket noch im selben Halbjahrzehnt bearbeiten, in dem du es eröffnet hast, aber ich werde versuchen, was ich kann).
ΔΔΔ Wegen des ICU-Tokenizer-Fehlers werden sowohl chocоlate als auch lateоchoc in drei Token zerlegt: choc + о + late. Die Tatsache, dass sie nicht in der richtigen Reihenfolge stehen, ist für das Matching normalerweise weniger wichtig als die Tatsache, dass sie sehr nah beieinander liegen. Die Tatsache, dass zwischen ihnen keine Leerzeichen stehen, spielt keine Rolle.
◊◊◊ Das ist ein großer Schritt nach vorn! Vor dem Auspacken war es gar nicht möglich, Verbesserungen in allen Sprachen zusammen vorzunehmen.
↓↓↓ Ein weiteres meiner persönlichen Problem-Auas ist die Tatsache, dass ich bei der Suche nach NASA nicht N.A.S.A. finde, und umgekehrt. Und ich möchte wirklich, dass alle (vernünftigen – siehe Fußnote Δ) Varianten von Hawaiʻi miteinander übereinstimmen. Ich wünschte, ich könnte everything, everywhere, all at once in Ordnung bringen!
☞☞☞ Gefallen dir meine Fußnoten-Symbole? Hasst du sie? Hey, ich versuche nur, die Klassiker wieder aufleben zu lassen!
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation