Originalmente publicado el 27 de junio 2024 por Silvia Gutiérrez, responsable del programa Bibliotecas (Fundación Wikimedia) y Giovanna Fontenelle, con el título LD42023 V: Main Challenges of Wikidata for Librarians
Durante los pasados meses Silvia Gutiérrez y Giovanna Fontenelle (miembros del Equipo de Cultura y Patrimonio de la Fundación Wikimedia) han estado publicando una serie en el Diff analiazando el resultado de la sesión colaborativa sesión colaborativa en la que se buscaba establecer un puente directo entre la comunidad Bibliotecas-Wikidata y la WMF duranet ela 2023 Conferencia LD4 sobre Datos Enlazados.
Esta es la quinta entrega de esta serie en la que se produnxiza en la cuarta diapositiva del taller, los retos que los participantes identificaron, especialmente en relación a herramientos, cuando usan Wikidata como bibliotecarios. En este caso, se les pidió separar sus respuestas entre herramientas concretas y aspectos, además de las razones por las que pensaban que suponía un reto. También se les sugirió marcar con emojis las herramientas (🧰) y el ADN (🧬) cuando estuvieran de acuerdos con lo recogido en el post-it virtual.

OpenRefine
La herramienta más comentada en el Jamboard fue OpenRefine, la cual es “…a una herramienta libre para trabjar con datos que se puede usar para procesar, manipular y limpar datos tabulares (hojas de cálculo) y conectarlos con bases de conocimiento (…) Está muy extendido su uso entre bibliotecarios, en el sector cultural, por periodistas y científicos, y forma parte de programas formativos y talleres por todo el mundo” (OpenRefine page on Meta-Wiki). Esta herramienta también tiene un amplísimo uso por Wikimedistas para cargar datos en Wikidata y, desde 2022, también para la carga masiva de ficheros y datos estructurados en Wikimedia Commons. Es interesante señalar que en nuestro artículo previo –sobre herramientas que nos gustaban e interesaban – OpenRefine era la que tenía más votos, 4 en total. No obsatnte, aparece también aquí.

En algunos de los comentarios, los participantes resaltaban aspectos difíciles de la herramienta, especialmente con respecto a su uso con Wikidata, como: “[Puede suponer un reto reconciliar nombres muy comunes cuando no existen muchos otros datos para diferenciar una identidad de otra en un registro de autoridades”. Esto es especialmente cierto en Wikidata, dado que hay una gran cantidad de nombres en el proyecto, y a veces sin demasiado contexto para diferenciar entre ellos. En esos casos, la mayor parte de las personas necesitan hacer comprobaciones una a una para evitar errores. En la misma línea, se señalaron problemas con la reconciliación de la propiedad “instancia de” y el uso de esquemas. Alguien incluso hizo notar que “la reconciliación puede ser una carga pesada” y planteaba el reto “¿Cómo se puede simplicar todo eso?”
Siguiendo con OpenRefine, se plantearon problemas como sus fallos y lentitud: “No corre con suavidad todas las ceces – especialmente con sistemas que son lentos” y “Las hojas de cálculo de Google y OpenRefine empiezan a fallar cuando se está construyendo grandes conjuntos de datos desde Wikidata”. Estos problemas suponen importantes consideraciones. Aunque puede costar superar algunos de estos problemas, también es cierto que sigue siendo una de las herramientas más valoradas y usadas, y ahora se puede aprender a usasr desde cursos en WikiLearn como “OpenRefine para Wikimedia Commons: conceptos básicos“, al cual se puede acceder teniendo una cuenta de usuario Wikimedia.
Consultas SPARQL
El siguiente aspecto mencionado en el Jamboard fue SPARQL y, en total, recibió cinco emoticonos del tipo DNA (🧬). Estos comentarios se refieren al Wikidata Query Service (o al Wikimedia Commons Query Service), la plataforma que los Wikimediastas usan para extraer información de Wikidata. Para hacer funcionar estas consultas de datos, estas herramientas usan SPARQL, que es “… un lenguaje semántico de consulta a bases de datos” según la Wikipedia en inglés. Este lenguaje tiene, es verdad, un aprendizaje alago difícil como comenta uno de los comentarios resaltados: “Dificultad de entenerlo (1 🧬)”.
Al igual que pasa con OpenRefine, los participantes también señalaron algunos problemas técnicos: “Las consultas SPARQL a veces producen time out, o devuelven resultados icompletos que, sin embargo, no aparentan serlo”. También se aportaron sugerencias sobre cómo se podría resolver esto: “Formas sencillas de filtrar consultas SPARQL con más criterios, como la presencia o ausencia de referencias” Este último comentario recibió tres DNA emojis (🧬).
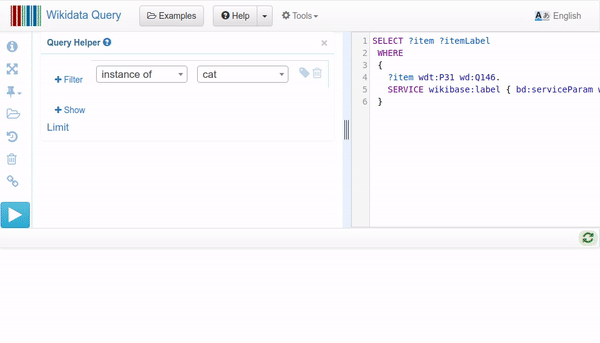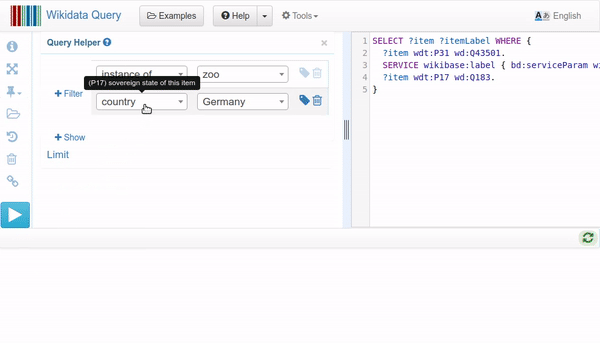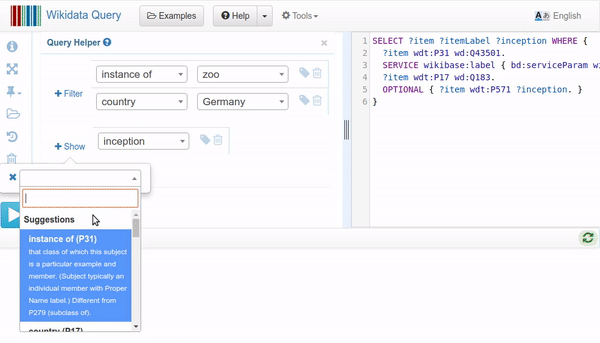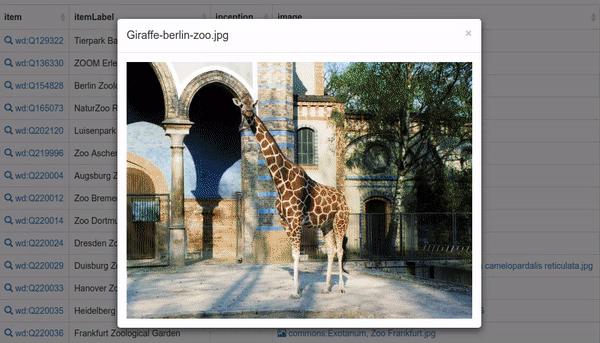
Cómo usar el Query Helper para editar una consulta SPARQL (Jonas Kress (WMDE), CC BY-SA 4.0, via Wikimedia Commons)
{kind=link}
Otros aspectos
El resto de aspectos que los participantes señalaron durante el taller, además de las herramientas, abarcan conceptos generales sobre Wikidata que pueden dividirse en dos grupos:
1 – Inconsistencias Semánticas
Este es uno de los comentarios con más 🧬 (7); la parte más dificultosa es la inconsistencia semántica. Estos son todos los comentarios en Jamboard sobre esto:
- “Las inconsistencias semánticas existentes en los datos de Wikidata que tienen que afrontarse antes de que un dataset sea usable (y los datos incompletos)
- “Un concepto está ahí, pero no tiene etiqueta en mi idioma”
- “Confución ontológica sobre qué es un instancia de qué”
- “Intentar normalizar un modelo de datos en un dominio cuando otros editores han seguido prácticas incosistentes. No solo quiero editar elementos para que se ajusten a mi modelo, pero no conozco una solución mejor”
- “Cuando el modelo de dato está determinado por correspondencias 1:1 con artículos de Wikipedia puede ser duro hacer ajustes”
- “Conceptos confusos – la idea sobre un concepto se solapa o varía entre diferentes culturas (por ejemplo, anglo-americanos vs. otros);”
- “Etiquetas en forma singular pueden causar problemas de reconciliación en OpenRefine si se mapea contra un vocabulario que usa el plural;”
- “Esta es una de las fortalezas y también debilidades de Wikidata: cualquiera puede añadir cualquier cosa a un elemento, lo que al final hace que se recuperen resultados difícil e incosistente”
- “Otras personas que posteriormente cambian tu modelo de datos (para que sea más consistente con el suyo propio) — no estoy seguro de si es un problema, pero su un desacuerdo.”
Todas estas consideraciones son extremadamente importantes y válidas. Hay dificultades por las que todos los editores de Wikidata tienen que pasar en su proceso de comprender y participar en Wikdiata. Una sugerencia que proponemos para aquellos que quieren explorar un poco más estos aspectos, es buscar un Wikiproyecto en Wikidata que esté alineado con el modelado de datos que interese para entender o ayudar a establer consistencia semántica. Por ejemplo, en el Wikidata:WikiProject Heritage institutions se intenta determinar qué propiedades tienen que usarse conforme al modelo de propiedades de Wikidata para los elementos de insitituciones del patrimonio y la memoria, como museos, bibliotecas y archivos.
2 – Notabilidad o Relevancia
El resto de los principales comentarios en el Jamboard tenían que ver con la notabilidad (o relevancia) de los datos, tanto en el momento de añadir nuevos datos como en el de los datos que se recuperarían. Estos son los comentarios que reflejaban esta dificultad:
- “Preocupación sobre la calidad de los datos para su reutilización en otros sistemas como entornos de descubrimiento”
- “Dudas sobre notabilidad cuando estoy trabajando sobre música global. Hay fuentes que uso que no suelen estar disponibles en bibliotecas”
- “Es más fácil colaborar en la validación y mejora de items”
Los aspectos de notabilidad son difíciles, especialmente cuando se asocian con problemas de inconsistencia semátncia. Una de la razones por las que se necesita consistencia es que se necesita poder dialogar con otras bases de datos y ser reutilizable.
Aparte de esto, la notabilidad o relevancia es también una preocupación que puede excluir temas, fuentes y referencias que no se consideran suficientemente notables para ser usadas debido a ciertos sesgos (género, idioma, origen, etc.). Para comprender la notabilidad en Wikidata, se puede consultar Wikidata:Relevancia. Al final de esta política, la comunidad Wikidta también recoge: “Si los datos que estás intentando añadir quedan fuera de estas pautas de relevancia (…) nuestros proyetos hermanos, Wikibase Cloud y Wikibase Suite podrían ser un buen lugar donde alojar tus datos. Entar en wikiba.se para aprener más sobre estas opciones.”
¡Este es el quinto de seis colaboraciones en este blog! ¿Quieres leerlas desde el principio? Aquí están los enlaces a las entradas anteriores (no todas están traducidas aún):
- #LD42023 Parte I: El futuro de Wikidata + Bibliotecas (Un taller)
- #LD42023 II: Conociéndonos entre nosotros, Bibliotecarios en el mundo Wikidata
- #LD42023 III: The Examples, Libraries Using Wikidata (english original version)
- #LD42023 IV: Wikidata Tools everyone is talking about (english original version)
- #LD42023 V: Principales retos de Wikidata para bibliotecarios (¡este artículo!)👈
- #LD42023 VI: Imagining a Wikidata Future for Librarians, Together
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation