I servizi di supporto di Wikimedia CH non si limitano alla Svizzera. Questa volta, un progetto si spinge fino in Tunisia. Uno studente in medicina ha avuto l’idea di ottimizzare le conoscenze libere su malattie, sintomi, farmaci, interazioni con altri farmaci e molto altro. Con l’aiuto dell’intelligenza artificiale e di un numero infinito di test, egli sta tuttora lavorando per rendere in futuro le domande di Wikidata nel settore medico molto più efficienti. L’obiettivo è trasformare Wikidata in una risorsa semantica biomedica su larga scala che copra in modo significativo la maggior parte degli aspetti della pratica clinica.
Questo studente di medicina è Houcemeddine Turki (Utente:Csisc). Chiunque legga il profilo del trentenne capirà subito da dove viene l’ispirazione per un progetto così mastodontico: Houcemeddine Turki è un ex membro del consiglio direttivo del Wikimedia TN User Group e del Wikimedia and Libraries User Group, membro del Wiki Project Med, collaboratore attivo di Wikipedia e Wikidata ed ex amministratore di wiki in prova presso il Wikimedia Incubator. È stato coinvolto nella creazione della prima struttura di ricerca legata a Wikimedia nel suo Paese, chiamata Data Engineering and Semantics, e ha fatto parte del core team di diverse conferenze Wikimedia, tra cui Wikimania, WikiIndaba e WikiConvention Francophone. Nel 2015 si è candidato al consiglio di amministrazione della Wikimedia Foundation. La sua proposta di invitare i professori emeriti a contribuire a Wikipedia è stata premiata con il primo posto nel concorso della campagna IdeaLab Inspire 2017.
Grazie a questa esperienza nel mondo wiki e al suo crescente background medico, si è reso conto che i database strutturati sono una risorsa importante anche nel settore sanitario. Offrono informazioni dettagliate su malattie, farmaci, geni o proteine, semplificando così l’elaborazione e la presentazione di informazioni cliniche di ogni tipo. Tuttavia, l’introduzione di tali risorse è particolarmente difficile nel Sud globale. Spesso mancano le risorse finanziarie e le competenze necessarie.
Piattaforme di conoscenza aperte come Wikidata potrebbero aiutare a superare questi ostacoli. Tuttavia, Wikidata presenta una serie di lacune: l’informatica biomedica è rappresentata in modo inadeguato. Gli esperti, infatti, diagnosticano incongruenze critiche nei dati esistenti. Houcemeddine Turki, con il suo progetto, vuole porre rimedio a questa situazione.
Così facendo, egli non solo intende trasformare Wikidata in una risorsa semantica biomedica, ma anche validare le informazioni biomediche liberamente disponibili in Wikidata. Inoltre, vuole promuovere Wikidata per l’uso dei dati biomedici nel Sud del mondo.
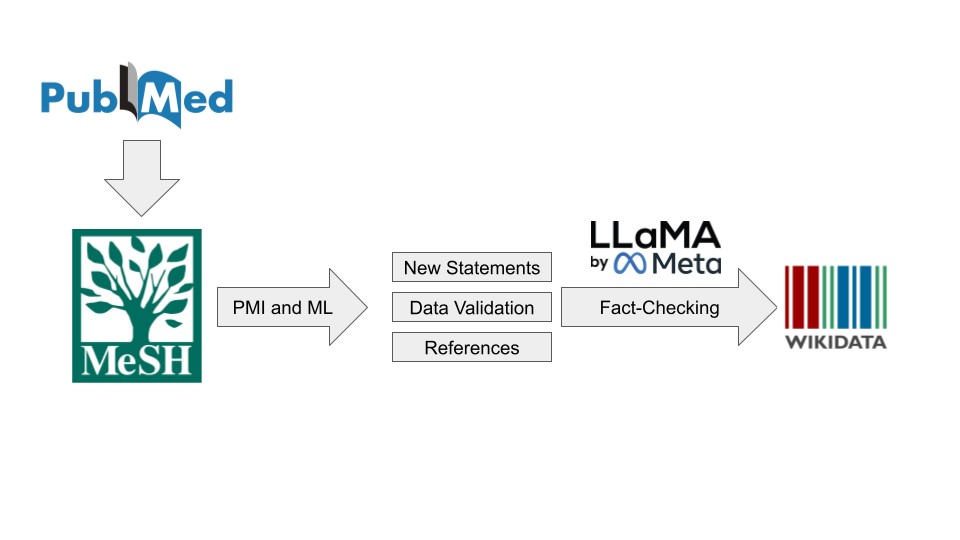
La Wikimedia Foundation ha concesso una borsa di ricerca per questo progetto. Il Programma per l’innovazione di Wikimedia CH ha messo a disposizione uno dei suoi 20 server per i test approfonditi, che richiedono un’enorme quantità di potenza di calcolo. Quello che viene fatto su questo server è un altro livello del progetto per rendere più robuste le informazioni biomediche in Wikidata.
Con grande passione, lo studente di medicina spiega tutti i processi tecnici che sono necessari per ottimizzare la rete di informazioni e che combinano il data mining, l’apprendimento automatico e il nuovo campo in evoluzione dell’intelligenza artificiale generativa. Per i non esperti, questa materia piuttosto complessa si trasforma rapidamente in una giungla impenetrabile di termini tecnici, formule e algoritmi. Ma alla fine è evidente che il mondo della conoscenza medica liberamente accessibile farà un grande passo avanti grazie al lavoro di Houcemeddine Turki. Wikimedia CH è orgogliosa di aver dato almeno un piccolo contributo a tutto ciò.
Nel dicembre 2024, Houcemeddine Turki ha condiviso con noi alcune scoperte:
- Abbiamo trovato un nuovo modo per verificare l’attendibilità delle risposte LLM alle domande vero-falso.
- Abbiamo usato il nostro metodo per verificare i risultati dell’estrazione di relazioni biomediche da PubMed prima di aggiungerli a Wikidata.
- Le tecniche di information retrieval possono essere utilizzate per identificare migliaia di relazioni mancanti in Wikidata. Stiamo cercando di capire come utilizzare gli LLM per esaminare dati così vasti, in modo da ridurre significativamente il carico di lavoro legato alla validazione dei dati.
Per saperne di più
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation