稲門ウィキペディアン会の Eugene Ormandy です。本稿では、大向一輝さんの論考「識別子としてのWikidata」を紹介します。
書誌情報
- 大向一輝「識別子としてのWikidata」『情報の科学と技術』第70 巻第11 号、2020年、559-562頁。https://doi.org/10.18919/jkg.70.11_559
要約
第1章「はじめに」
著者は第1章にて、この論考の要旨を述べます。以下、559ページより引用します。
本稿では、Wikipediaとの関係を手がかりに、識別子としてのWikidataの特徴について述べる。また他の識別子との連携事例や、言葉に識別子を与えるWikidataの新たな取り組みを紹介する。
前掲書、559ページ。

第2章「WikidataとWikipedia」
第2章にて著者は、Wikipediaでの活用の観点からWikidataの意義と機能について述べます。
まず著者は、同一概念に対するWikipedia記事が複数の言語版上に存在するようになった結果、言語間リンクが増加して管理が困難になったという事例を紹介し、この事態を受けてWikimedia財団は、Wikidataによって言語間リンクを集中的かつ機械的に管理する方針を採用したと述べます。これにより、各言語版での言語間リンクの維持コストは大幅に低減したとのこと。
続けて著者は、項目名の文字列そのものがURIの一部をなすWikipediaは「特定の項目名を含むURIがどの同音異義語を指すか、あるいは曖昧さ回避のページを指すかは事前に予測できない」と指摘します。たとえば「https://ja.wikipedia.org/wiki/アップル」が、企業「アップル」のページを表示するのか、それとも「アップル」の曖昧さ回避ページをするのかが事前に予想できないということですね。
そして第2章の最後に著者は「これに対して、Wikidataでは識別のために自然言語を用いない点が特徴的である。(略)同音異義語についても、設計上それぞれに異なる識別子が与えられているために重複が生じない。このように、Wikidataでは概念自体を識別することで、項目名を中心に構成されたWikipediaの情報のあり方を補完する役割をになっている」と述べます。
第3章「Wikidataの識別子」
第3章は2つの節から構成されます。
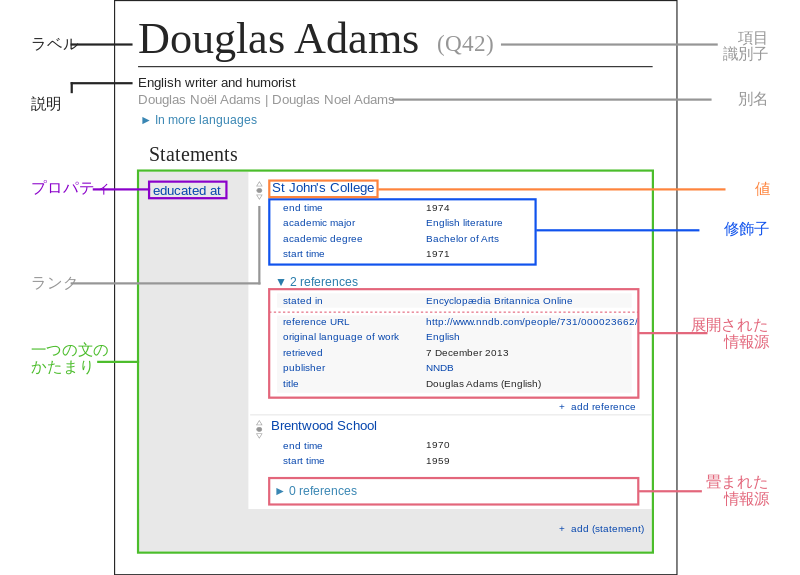
第3章第1節「項目と属性」で著者は、項目 (item)、属性 (property)、値 (value) といった、ウィキデータの基本的な情報を紹介します。なお、これらの情報はウィキデータの [[Wikidata:はじめに]] というページにまとめられているので、興味のある方はご覧ください。また、著者は本節にて、Wikidata の検索等が可能なサービス Wikidata Query Service にも言及しています。
第2節「辞書学データ」では、言葉を対象として識別子を付与する辞書学データ (lexicographical data) が紹介されます。語彙素 (lexeme)、語形 (form)、語義 (sense) という基本的な情報を取り上げたのち、著者は「QID(引用者註:通常のウィキデータ項目のID)が言語によらない概念を対象としていることに対して、辞書学データは言葉自体のデータ化を目指している。その意味では Wikipedia における項目名の詳細化とも言えるが、百科事典が対象とする項目名だけでなく、動詞や形容詞などの登録を受け入れていることからその範囲は広い。これらの枠組みを活用して方言を整理するなどの取り組みが行われており、グローバルかつ言語の多様性を考慮した辞書として成長していく可能性を秘めている」と評しています。
第4章「識別子のハブ」
第4章で著者は、ウィキデータが他の識別子との関係性を明示するハブとしての機能する仕組みを紹介します。具体的には、ウィキデータの項目に米国議会図書館管理番号や国立国会図書館典拠 ID といった識別子が付与されている仕組みを説明し、「通常、個別の識別子には他の識別子との関連は明記されていないが、Wikidata のコミュニティによってそれらが相互に関連付けられることで利便性が大きく高まることが期待できる」と評します。

また、著者は「Wikimedia 財団が運営するサイト以外にも Wikidata の識別子を採用する事例が増えている」と指摘し、所蔵品の検索サイトに Wikidata の QID をリンクしたニューヨーク近代美術館の事例や、テレビ番組等のデータを1話単位で作成するメディア芸術データベースが、作品レベルで項目を作成するウィキデータに複数のデータをリンクさせる事例を紹介します。
第5章「課題と展望」
最終章で著者は以下のような指摘をしています。
- Wikidata の完全性や正確性を担保することは困難であり、Wikipedia と同様に長期的な信頼性を得るための枠組みと捉えるべき。
- Wikidata が主流になるにつれ、外部の識別子をリンクするだけでなく、データの全面的な取り込みや、プロジェクト自体の引き継ぎも増えていくものと思われる。
- Wikidata はデータの公開に加えて Wikidata Query Service などを通じて機械的な連携を可能にする基盤が整備されている。これは Wikipedia のデータ連携が第三者のプロジェクトである DBpedia に依拠していることとは大きく異なる。
感想
自分がウィキデータを編集しながら断片的に学んでいた情報を体系的に整理することができ、大変勉強になりました。同時に、体系的に理解していなくてもなんとなく編集できてしまうのがウィキデータ、ひいてはウィキメディア・プロジェクトの面白い点(そして怖い点)なのだなということも気づきました。
もちろん、知らない情報も色々と仕入れることもできました。例えば、Google が運営した知識ベース Freebase が2016年に閉鎖されて Wikidata に移行されたという事例は全く知りませんでした。
また、論考の趣旨とは少しずれますが「Wikidata が主流になるにつれ、外部の識別子をリンクするだけでなく、データの全面的な取り込みや、プロジェクト自体の引き継ぎも増えていくものと思われる」という指摘は、ウィキメディア・コモンズとデジタルアーカイブにも通じる話だなと感じました。
興味を持った方はぜひ読んでみてください。オープンアクセスなので、JSTAGE から無料で全文読めます。https://doi.org/10.18919/jkg.70.11_559