A galloping overview
As we have done before, let’s get a bird’s-eye view of the parts of the search process: text comes in and gets processed and stored in a database (called an index); a user submits a query; documents that match the query are retrieved from the index, ranked based on how well they match the query, and presented to the user. That sounds easy enough, but each step hides a wealth of detail. Today we’ll focus on the last part of the step where “text gets processed”—and look at stemming, stop words, and thesauri.
Also keep in mind that, as discussed in more depth in the first installment in this series, humans and computers have very different strengths, and what is easy for one can be incredibly hard for the other.
The magic of morphology[1]
For the most straightforward kinds of search, the most important element of the grammar of most languages is morphology—the study of how words are put together from smaller pieces; in English, these pieces are generally prefixes, suffixes, and stems (also called roots in some grammatical traditions). Other elements of grammar, such as phonetics and phonology (relating to sounds) and syntax (how words are built up into sentences) usually don’t matter as much for search—though for some languages, the boundaries between such elements can be a lot blurrier than they are in English.
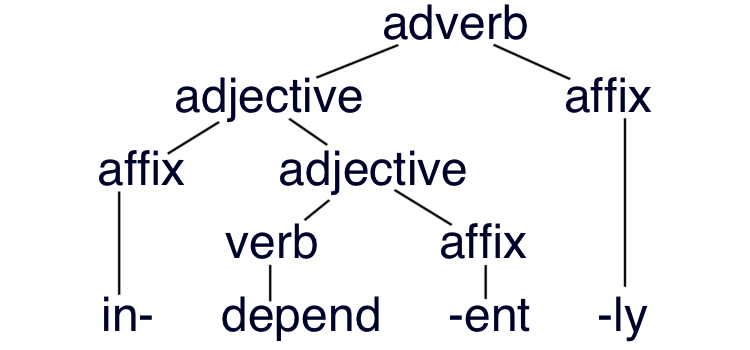
In addition to prefixes at the beginning and suffixes at the end of words, other languages have infixes in the middle—English has a limited set of slangy infixes, as in the lightly bowdlerized absofreakinglutely or hizouse (see more English infixes from Wiktionary)—and multi-part circumfixes that go around another word.
Other interesting morphological phenomena include:
- clitics, which are morphological elements that act like words syntactically, but like affixes phonologically.[2]
- reduplication, which repeats all or part of a word, as in English “schm-reduplication” (e.g., fancy-schmancy) or “contrastive focus reduplication” in which the repeating of an element indicates that it is “real” or “pure” or “prototypical” (as in, “you can put a bucket on your head and call it a hat, but that doesn’t make it a hat-hat”).
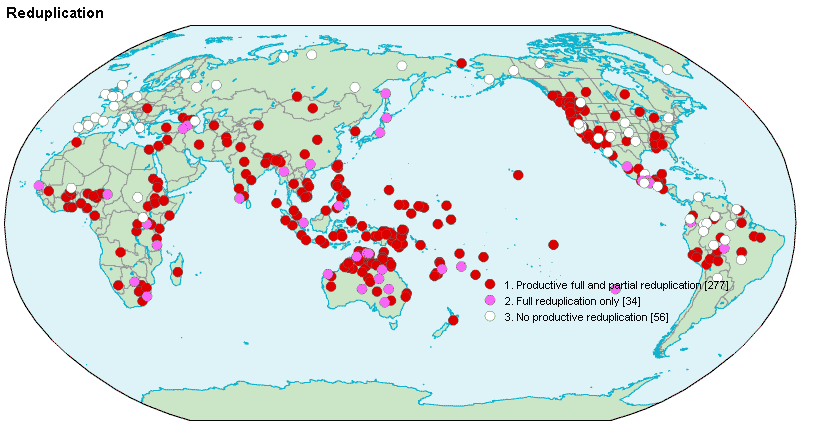
- noun incorporation, in which a noun gets folded into a verb to limit its scope. English has a wee bit of such incorporation in words like backstabbing or babysitting, but some languages do it much more frequently and with vigor!
- ablaut and umlaut, in which a vowel change indicates an inflection. There are remnants of these processes in English in paradigms like foot/feet and sing/sang/sung that are now considered irregular. In other languages, like German, this is a common regular process.
So, generic English morphology is rather boring as these things go. That turns out to be good for search in English because the general morphological rules are comparatively simple (despite the interesting irregular exceptions, and the fact that English spelling is atrocious—which does sometimes make things a bit harder than they need to be).
The root of the problem
The reason that morphology matters for search is that we generally want related forms of a word to match each other when we perform a search. For example, English hope, hopes, hoped, and hoping are all reasonable matches if you search for hope. This is generally accomplished through a process called stemming, which tries to reduce a word to an approximation of its stem or root form.
For you hard core text analysis nerds out there, we can distinguish stemming from lemmatization. The goal of stemming is for all words that are related to be reduced to the same stem (even if that stem is not the true root form or even an actual word) and for unrelated words to be reduced to different stems. Lemmatization, on the other hand, is only successful if the result is the “lemma” of a word, or the exact root form of a word, like you’d expect to find in a dictionary. This is the definition of lemma that is used in so many categories on English Wiktionary. Since “lemma” is its own lemma in English, one of its categories is “English lemmas” (and another of its categories is “English autological terms”—neat!).
Trying to generate lemmas is in theory a good way to do stemming because if the results are true lemmas, then words with the same stem are going to mostly be related to each other.[3] However, in practice, because English spelling is atrocious,[4] generating accurate lemmas can be expensive because it often comes down to having an extensive list of exceptions—and not just for the obvious irregular paradigms like be/am/is/are/was/were, child/children, ox/oxen, sing/sang/sung, etc.[5] However, as alluded to above, sometimes a somewhat inaccurate rule will suffice.

For example, the lemma of begging is beg, but the lemma of egging is egg (yep, it can be a verb). A general stemming rule that replaces -gg and -gging with -g, for example, will give an non-lemma stem for egg and egging of eg, and will conflate names like Flagg and Bragg with the more common words flag and brag, but overall it works pretty well for words ending in g. The stemmer we use on English-language wikis doesn’t actually use this specific rule, though, because English morphological analysis is generally well-developed, and there are very large (but still never complete) dictionaries in use behind the scenes.[6]
Despite the challenges offered by English spelling, English morphology is comparatively very easy. There aren’t that many forms to contend with: -s, -ed, and -ing cover most inflected forms of nouns and verbs. A few other derivational forms like -ly and -er are used to make related words.[7] Compare that with a few dozens forms of a Spanish verb and a couple thousand forms for a Finnish noun (so many cases!—though many combinations may never come up, they are very regular, which makes them relatively easy to generate and understand).
English is fairly analytic, so we use word order, and other separate words like auxiliaries and prepositions to indicate the grammatical relations in a sentence. Agglutinating and polysynthetic languages can smash a whole sentence into a single “word”. A favorite example among linguists is Ubykh’s “aχʲazbatɕʼaʁawdətʷaajlafaqʼajtʼmadaχ,” which means “if only you had not been able to make him take it all out from under me again for them.” For Ubykh (which, unfortunately, has gone extinct), any morphological software would have to be a lot more complex than what we have for English.
Balancing accuracy and complexity
For stemmers in general there are always potential trade-offs between accuracy and complexity. Fortunately stemming in many languages is an 80/20 kind of problem—so you can get good results with a fairly simple process, while on the other hand you may never reach 100% accuracy.
The simplest stemmers are typically rule-based, and simply try to remove affixes from a word and maybe change the resulting stem a little bit so it is more likely to match other related stems. These stemmers are fast and work on words they’ve never seen before, but also may make more mistakes,[8] and may or may not handle common exceptions (like be/been/is/am/are/was/were or sing/sang/sung in English). A very influential rules-based stemmer for English is the Porter Stemmer.
More complex stemmers or lemmatizers can use a dictionary for exceptions, and then apply rules to anything that’s not in the dictionary. Of course, the dictionary still can’t handle words it doesn’t know, though you can have heuristics to try to match parts of words, too, so that a dictionary entry for national could apply to international, multinational, transnational, binational, supernational, subnational, supranational, etc.
A much more complex approach is to use a statistical or machine-learning model, which should be able to generalize from the examples it trained on to new ones that are similar. Such models can find and exploit interesting patterns, but can also give terrible answers when given really unexpected input. For example, Elasticsearch—the search engine that our on-wiki search is built on—endorses a statistical stemmer for Polish that we deployed on Polish-language wikis; it does a good job on the vast majority of Polish words, but sometimes goes a bit off the rails when it gets input consisting of certain numbers or English words—which, of course, occur often in the Polish Wikipedia![9] We’ve since added filters to ignore the most predictable and egregious errors; we now rely on exact matching for those search terms, which we’ll talk about more in a later post on indexes.
As mentioned in footnote 3—you are reading the footnotes, right?—some forms are ambiguous on their own. For example, can can mean “to be able to” or can be a metal cylinder, and does can be a form of do or the plural of doe. Recognizing parts of speech—e.g., nouns, verbs, adjectives, adverbs, etc.—can help in cases like this, since these ambiguous forms differ in their part of speech. However distinguishing others, like putting—which can be a form of put or of putt—would require an incredible level of contextual and real-world information—the kind of thing that is easy for humans and hard for computers: “After putting the ball into the hole, I saw her putting the club into her bag.” This level of natural language processing is often not available, and is generally not worth the massive increase in complexity to bump stemming performance from 99% to 99.9% accuracy.
The stemmer used on English-language wikis comes bundled with Elasticsearch, which provides stemmers and other language processing for almost three dozen languages; third-party plugins are also available for others, like Polish. For languages with a larger search volume and no language analysis plugins from Elasticsearch, we’ve adapted other third-party open-source morphological analysis software for use with Elasticsearch. We’ve adapted software for Slovak and for Bosnian, Croatian, and Serbian; we worked with a developer to build something new for Esperanto; and we were able to apply existing analysis software for Indonesian to Malay.[10] The new stemmers for Bosnian, Croatian, and Serbian, Slovak, and Esperanto aren’t perfect, but they do take advantage of the 80/20 nature of stemming, and have improved the quality of search results in those languages.
To be or not to be indexed
Once we’ve got our stemmed forms of the words from our text, we might want to throw some of them away! “Stop words” are words that don’t usually carry a lot of meaning and appear frequently—often function words like prepositions (to, of, at, from) and determiners (a, an, the) or common, generic words (like make, do, be)—and so can be ignored and not put in the index. Back in the very early days of full-text search, there was also a matter of saving space in the search index, because stop words tend to occur frequently; nowadays that’s usually not much of a concern.
The problem is that sometimes a useful phrase can be made up entirely of stop words. Choosing the exact list used for any application is more of an art than a science, but be, not, or, and to are all common enough stop words, reducing the famous quote from Shakespeare—“To be or not to be”—unfindable!

One solution is not to have any stop words and use frequency analysis to discount words that would otherwise likely qualify as stop words. For example, lexicalism occurs in only five articles on English Wikipedia, while of occurs in 5.4 million. It’s easy to guess which word is more relevant to our query.
Another approach is to have multiple indexes—some with stop words and some without—and merge their results. We’ll talk more about that in a later post.
A rose by any other name
Some search engines support a thesaurus, which allows you to effectively insert synonyms or other related terms into a document, even though they aren’t actually there. For example, while there is a distinction between an attorney and a lawyer, many people outside the legal profession use them interchangeably. A thesaurus could add attorney wherever lawyer occurs, and vice versa.
Elasticsearch supports a thesaurus, but we don’t currently use one on-wiki. The search system we had before Elasticsearch has exactly one entry in its English thesaurus—film ↔︎ movie—which makes a lot of sense for English Wikipedia!
Building and maintaining a thesaurus that’s any bigger than that has traditionally required careful planning and knowledge of the search domain—which for Wikipedia is pretty much everything. However, some researchers have gotten good results from automatically generated thesauri that use co-occurrence of terms in documents to find related terms; these thesauri are often less about specific synonyms and more about expanding a search with useful related terms.
We don’t currently have any concrete plans to build or enable thesauri for on-wiki search, but it is on our long-term radar.
Further reading / Homework
Amir Aharoni, Language Strategist at the WMF, did a nice presentation titled “The English Language as a Privilege” that touches on a lot of the ways that computers are better at dealing with English, whether because of particular features of English, as we discussed above, or because of the fact that many computer systems were originally developed by English speakers.
If you can’t wait for next time, I put together a poorly edited and mediocrely presented video in January of 2018, available on Commons, that covers the Bare-Bones Basics of Full-Text Search. It starts with no prerequisites, and covers tokenization and stemming, inverted indexes, basic boolean and proximity retrieval operations, TF/IDF and the vector space model of similarity, field-level indexing, using multiple indexes, and then touches on some of the elements of scoring.
Up next
In my next blog post, we’ll look at inverted indexes and maybe touch on queries and retrieval operations.
Trey Jones, Senior Software Engineer, Search Platform
Wikimedia Foundation
———
Footnotes
1. Or, one could say, “the glamour of grammar”—glamour has a older and now less common meaning: a magical spell. We know that glamour came to English through Scots, and one possible previous step in its etymology is that it branched off an earlier English meaning of grammar, which is given in Wiktionary as “any sort of scholarship, especially occult learning”. By the way, the letter r changing to an l isn’t at all out of the question; it’s a kind of sound change called dissimilation and it often happens to r’s and l’s. It explains the pronunciation/spelling split in English colonel, and the difference between the related words pilgrim and peregrine (both kinds of travelers or wanderers).
2. Clitics are interesting, but complicated, so their more complex explanation is relegated to a footnote, alas. Some linguists argue differently, but English possessive -’s can be seen as a clitic. Phonologically—that is, sound-wise—it is not a separate word. Like past tense -ed or plural -s when spoken it is clearly part of the word it attaches to. But unlike -ed which must attach to a verb, or plural -s which must attach to a noun, possessive -’s comes at the end of a noun phrase, and so can end up attached to almost any part of speech.
Consider hats that belong to many different people: Robin’s hat (-’s attaches to a proper noun), the child’s hat (attached to a common noun), the boy whose hair is green’s hat (adjective); the girl who walks quickly’s hat (adverb), the person I’m thinking of’s hat (preposition), the person Fred said liked him’s hat (pronoun). Any word that can be placed at the end of a noun phrase can have -’s attached to it. Examples with determiners (like the) and conjunctions (like and) are only hard to come by because noun phrases don’t typically end with those parts of speech. But if we invoke the use–mention distinction and use quoted speech, we can find an example where -’s attaches to the, and create a train wreck of apostrophes in the process: the linguist who said “my favorite word is ‘the’ ” ’s hat.
3. Even with generally accurate lemmas, there are some problem cases. Some words are ambiguous, but only in certain forms. A good example is can, which can be a defective verb meaning “to be able”, a noun referring to a metal cylinder, or a related verb meaning to put things in cans. The forms canning and cans are clearly the metal cylinder kind, but their lemma, can, is ambiguous. Similarly, the verb do and the noun doe (a deer, a female deer) are not easily confused as lemmas, but the form does is, at least in writing. Similarly, putting could be a form of either put or putt. Have I mentioned that English spelling is atrocious?
4. I like to say that there aren’t really any spelling rules in English, only moderately useful suggestions. There are a few famous examples of the… uh… let’s say “idiosyncrasies”… of English spelling that always bear repeating: ghoti—with the gh in laugh, the o in women, and the ti in nation—sounds like “fish”. Mapping ghoughpteighbteau to “potato” is left as an exercise for the reader. Non-native speakers of English who want to torture themselves should try to read a brutal poem by Gerard Nolst Trenité about English spelling, appropriately titled “The Chaos”. Even native speakers of English may find it challenging. It’s available on Wikisource. For some insight into how we ended up with this mess, see more about the history of English orthography on English Wikipedia.
5. English be is an incomplete melding of three(!) different verbs, sing is an old strong verb, and children and oxen show the remnants of an older Germanic system of pluralization from Old English. Eventually, all of these irregularities may disappear—as many others already have—through a process known as leveling.
6. Those English dictionaries include some interesting mappings, too. For example, the stem for french is france, for german it’s germany, for italian it’s italy, for holland it’s dutch, and for filipino it’s philippines. This works out well for certain locutions in English, making “president of france” and “french president” essentially the same (see more on the treatment of of in the section on stop words). The fact that most pairs map the adjective to the country while holland and dutch go the other way doesn’t matter much because the result is only used internally by the search engine.
7. Affixes that give a variant of the same word (hope, hopes, hoped, hoping) are called inflectional affixes, while affixes that give a related but distinct word (like hope → hopeful, quick → quickly, word → wordy, or work → worker) are called derivational affixes. Stemmers generally try to unify words that are inflections of the root form. Whether or not derived forms should be included depends on the goals of whoever is creating the stemmer. It’s like deciding what forms to list in a dictionary. Should related forms—especially those whose meaning is predictable—all be listed under one headword (stem/lemma/root), or should they get their own entries? In English, words definitely belongs under word and hoping belongs under hope, but do wordy and hopefully get their own entries or not? It’s a judgement call.
8. A really common source of mistakes for rule-based stemmers comes from words that look like they have affixes on them, but don’t. For example, surnames like Belcher, Childers, or Johns, which can have their final -er, -ers, or -s stripped off. More common names, like Jones and Edwards, may be known exceptions and thus left untouched. Ironically, the name Stemmer is likely to be incorrectly but understandably stemmed to stem.
9. Some of the examples I found when reviewing the Polish stemmer are listed on MediaWiki. The worst is the stem ć, which is the infinitive verb ending in Polish. Lots of completely unrelated words—like Adrien, Button, Coins, Drag, Espinho, Frau, Girl, Hague, Issue, Judas, Keiki, Laws, Mammal, Nuxalk, Oloś, Pearl, Qaab, Rogue, Shingle, Trask, Uniw, Value, Wheel, XXIII, Yzaga, and Zizinho, just to name a few—get reduced to the ć ending by some overzealous bit of statistical machinery inside the stemmer. Fortunately the words that it makes mistakes on are fairly rare, and we’ve added filters to improve the results.
10. We have one stemmer for Bosnian, Croatian, and Serbian, and one for Indonesian and Malay. The languages in these two groups are closely related and have the same basic morphology even where they differ in vocabulary, spelling, pronunciation, or writing system. As an analogy, US and UK English differ in the spelling of color/colour or realize/realise, and in the vocabulary for truck/lorry, but the rules for inflecting those words are the same as general English words—colors/colours, realizing/realising, trucks/lorries—so the same stemmer can be used without knowing which variety we are dealing with. The situation is similar—but with potentially much more distinctiveness between varieties—for Bosnian, Croatian, and Serbian and for Indonesian and Malay.
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation