
{kind=link}
I work as a part of the Community Programs (GLAM) team at the Wikimedia Foundation. As part of my work, I support Wikisource, a digital library of public domain and freely licensed texts, which is an important platform for GLAM projects and knowledge exchange in many Wikimedia communities. I have been writing case studies about Wikisource, documenting pain points around it, and prioritizing them with the communities.
In order to learn even more about Wikisource and how it can be improved, my colleague Sandra and I co-mentored a small-scale GLAM pilot project around Structured Data on Commons. We worked with a few members of the Punjabi community around digitized texts on Wikisource. We wanted to ‘learn by doing’: can Structured Data on Commons help to improve and simplify the way in which we add materials to Wikimedia Commons and Wikisource? Can it help us make better and stronger connections between bibliographic data on Wikidata, digitized works on Commons, and transcriptions on Wikisource? What is possible with the current infrastructure, and what needs to be developed to better support this?
I had a conversation with Stalinjeet Brar and Satpal Dandiwal from Punjabi Wikimedians, and here is what we talked about:
Back in January 2019, the Punjabi community came across an interesting set of books belonging to the Qissa genre, a literary genre with Perso-Islamic roots that consists of storytelling in verse, from the private collection of Punjabi author Satnam Chana.
What makes these works interesting is the fact that very little information is available about them. For instance, the year of publication is not mentioned on almost all of them and most of the authors are anonymous.
“ Very little metadata was available to us about these works and their authors. We had to do a lot of research such as consulting with scholars of history of Punjabi literature and going through some of the histories of literature as well.”
– Stalinjeet

_-_1.jpg){kind=link}
A few works from the Qissa genre found at other online digital libraries, such as the Panjab Digital Library, were also included in the project.
Talking about the workflow, the very first step was to scan and post-process all the works followed by gathering metadata about these 20 odd works. Initially, this metadata (titles, authors…) was collected in MS Excel, and then the spreadsheet was imported into OpenRefine, a tool with which you can upload larger sets of data to Wikidata. However, Gurmukhi script was not rendered properly in OpenRefine from MS Excel. So, the community members tried copy-pasting the metadata to Google Sheets and then imported it into OpenRefine and that worked. Using the OpenRefine ‘reconciliation‘ functionality, it was easy to match the authors’ names with their Q numbers on Wikidata, and then new items on Wikidata were created about all these works and some missing authors using OpenRefine.
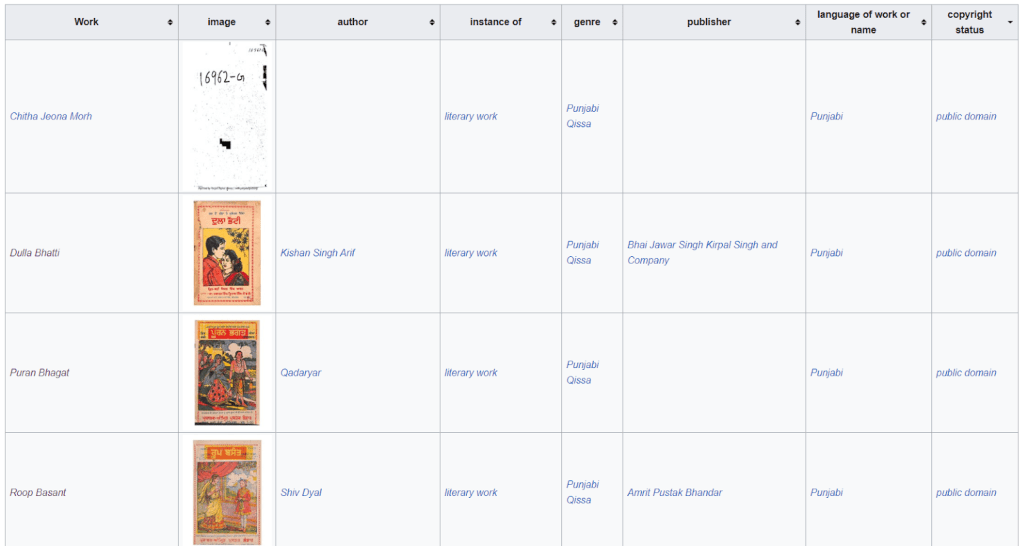
The community was able to identify the copyright status of only 6 out of the 20 works that we digitized: it was only possible in those few cases where we were able to identify an author with a known death date of more than 100 years ago, or a publication date.
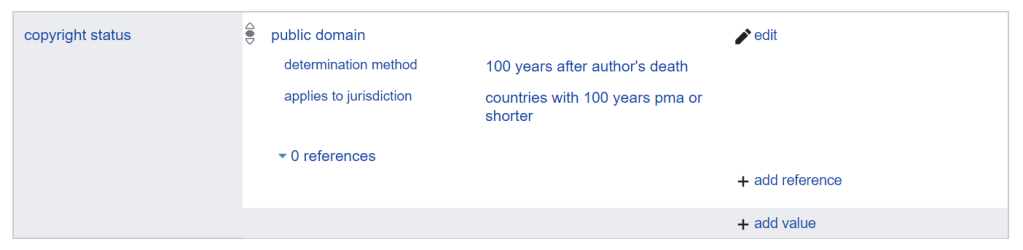
The copyright status of the works is included on their Wikidata items, and follows the guidelines that are being written by the Wikimedia community there – see Help:Copyrights on Wikidata for an extensive outline.
Once Wikidata items were created using OpenRefine, the community members felt it was easy to upload the works to Wikimedia Commons using the UploadWizard. Connecting Wikidata items with respective works in the Structured Data tab was also easy, although the community members weren’t sure what properties should be used on Wikimedia Commons (depicts (P180), digital representation of (P6243), or something else). We invite everyone to help us improve the structured data descriptions of the Wikidata items and of the uploaded books.

The scanned publication ‘Dulla Bhatti‘ 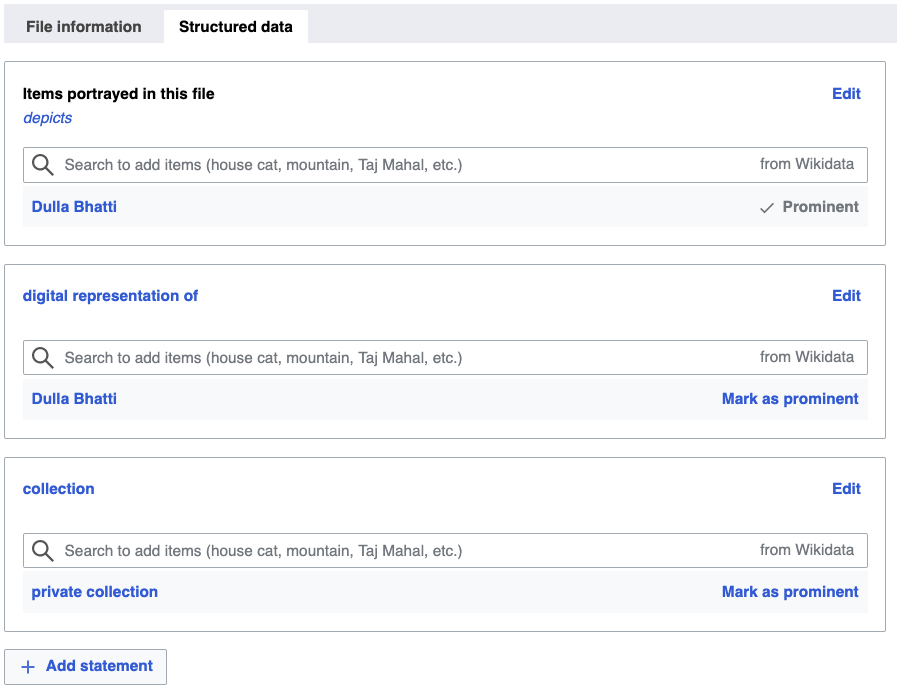
Structured data about this PDF file
“The entire workflow included extra steps than what I have been used to, such as creating items on Wikidata and connecting items with uploaded files on Commons using Structured Data.”
– Satpal
Community members feel that creating Wikidata items using OpenRefine is a complicated process and it needs to be simplified, especially if we are hoping that newbies and GLAM institutions might also be contributing using a similar workflow.
“Currently, OpenRefine is for advanced users and I think it needs to be more user-friendly.”
– Stalinjeet
Several of the books are now available on Wikisource, ready for transcription. If you speak Punjabi, feel free to lend a hand! Please note that the structured data from Wikidata and Wikimedia Commons is not included in the book pages there yet, as Punjabi Wikisource does not yet have Wikidata-driven templates.
Next steps – what are still general open issues?
- In the future, Structured Data on Wikimedia Commons can help us to avoid repetitive work and ‘data duplication’ in the Wikisource workflow: having to enter the same information about a publication three times, between Commons (describing the file), Wikidata (describing the publication itself), and Wikisource (providing information about the transcription). It is now technically possible to create a Wikidata item about a publication on Wikidata, and then to re-use that same data in the description of the file on Wikimedia Commons, and in the description of the work on Wikisource itself. The technical skills required to develop local templates to make that data visible on Wikisource, may not exist in the smaller language communities. And the user experience at the moment is still quite complex: you need to work with no less than three different websites in order to set up the transcription of a publication! Ultimately, we hope that this pilot helps us to make more sense of the ways in which Wikisource, and the transcription of sources on Wikimedia projects, can be simplified and improved in general.
- In this pilot project, the community members tried their best to describe the Punjabi Qissa books to the best of their ability, both on Wikidata and Wikimedia Commons. However, books are notably difficult to describe on Wikidata, because there are various layers of information about them (work, expression, manifestation and item). Community members in this pilot project didn’t have enough understanding around data-modeling of bibliographic works on Wikidata. We welcome any corrections and updates to the Wikidata items, especially by people familiar with WikiProject Books on Wikidata. Additionally, there is not an established consensus on how to describe information about a scanned book in structured data on Wikimedia Commons yet, so input and corrections there are very welcome too.
How can you help?
- Help describe the materials better. This pilot project is a first attempt at modeling things and experimenting with workflows, and your additions and corrections will help us all improve this process. You can also contribute comments and examples of Wikisource-related materials on the data modeling pages of Structured Data on Wikimedia Commons.
- Think, together with fellow Wikisource community members, about improved integration between Wikidata, Wikimedia Commons and Wikisource, and share your thoughts and experiments. Good places to talk about this issue are your local Wikisource, the above mentioned data modeling pages, and the talk page of WikiProject Books on Wikidata.
- Add your ideas for Wikisource improvement to Phabricator. Wikisource’s general workboard is available at https://phabricator.wikimedia.org/project/view/1117/.
- Do you code, and/or are you experienced in Wiki templates and Lua? Help us build Wikidata-driven templates on Wikisource.
- And of course, upload and transcribe publications from your own culture, experiment with structured data as well, and talk about your experiences with your fellow Wikisource volunteers, here on Wikimedia Space, or on your Wikisource.
This blog post by Satdeep Gill is part of a short series of blog posts on Wikimedia Space about GLAM pilot projects with Structured Data on Wikimedia Commons. Earlier posts are:
- Introducing ISA – A cool tool for adding structured data on Commons
- How we helped a small art museum to increase the impact of its collections, with Wikimedia projects and structured data
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation