Since 2019, files on Wikimedia Commons can be enhanced with multilingual and machine-readable structured data. This addition brings many benefits for cultural institutions or GLAMs (Galleries, Libraries, Archives and Museums) partnering with Wikimedians, as GLAMs also store data about their collections in very structured ways.
In the past year, I have worked together with GLAM staff and Wikimedia community members to ‘test’ this new technology, and explore its potential, in a series of pilot projects. What does Structured Data on Commons make possible? Which new questions and challenges appear?
- We have imported the collection of a small museum to Wikimedia Commons and Wikidata, in order to experiment with data modeling, and to explore the potential of structured data to make small collections accessible online for the first time.
- Community members have developed a micro-contributions game (the ISA Tool), testing the potential of ‘easy’ structured data editing for newcomers.
- Wikimedians have described digitized books with structured data, to prepare them for transcription on Wikisource, investigating how Structured Data on Commons can help to avoid data duplication across Wikimedia projects and how it can make cross-wiki workflows more efficient.
- Various organizations researched data synchronization and roundtripping with external databases – a feature that many larger GLAM institutions ask for, and for which structured data on Wikimedia projects provides more advanced foundations.
- A fifth pilot project has brought together, and connected, the work of three generations of prominent Belgian silversmiths, exploring the potential of structured data to connect art collections around the world and to link them to their broader context. This pilot also highlighted the description of copyright and licenses in structured data.
Working on this set of pilot projects, what were some of the most common new challenges we discovered for GLAM-Wiki projects using structured data? In most of these projects, we spent a lot of time thinking about data modeling, and about the right place to put certain data. Read on for more!
Creative works and media files: does the difference matter?
As Structured Data on Commons was under development, the Wikimedia Commons community started exploring how to best describe (GLAM) files with structured data on Wikimedia Commons. How should the community use properties and items from Wikidata to indicate who created a file, when it was created, what can be seen in it? In August 2018, community members started brainstorming a potential data model in the so-called properties table.
Advice from the cultural sector
The cultural sector itself has a lot of experience in storing digital media files and describing them. I have asked several GLAM staff familiar with such data modeling to look at the emerging data model expressed in the properties table, asking for feedback.
What was the most common pattern in the feedback we received? When dealing with files on Wikimedia Commons that show a creative work (for instance a photo of a sculpture or a scan of a book) it’s very important to make a clear distinction between the creative work, and the file that shows this work. Antoine Isaac, R&D Manager at the cultural aggregator Europeana, compiled a document with extensive comments, which includes a clear warning to avoid a situation of ‘Leonardo da Vinci creating thousands of JPEGs.’

{kind=link}
George Bruseker, Research and Development Engineer at Foundation for Research and Technology – Hellas (FORTH) is specialized in the CIDOC Conceptual Reference Model, a metadata standard for the cultural sector which is supported by the International Council of Museums. He provided feedback on the draft properties table and mapped part of this emerging data model to CIDOC CRM. Quoting him:
It is extremely important to make a crisp distinction between the description of the digital object qua digital object, and the various information objects that it encodes/carries/incorporates. If this is not done properly, there will be a lot of confusion and mistakes in the metadata and the Commons community will run into problems in the future!
George Bruseker

{kind=link}
{kind=link}
{kind=link}
{kind=link}
As seen in the examples above, this distinction matters for correct attribution and copyright determination, in line with the GLAM sector’s and Wikimedia’s own values of rigorousness and correctness. Many Wikimedians familiar with cultural heritage and structured data intuitively understand it and already bring it into practice. But it’s not intuitive to laypeople, and I’ve also heard some Wikimedians say ‘this is very hard’ and ‘this makes my head hurt’. Should we aim for precise descriptions that are more difficult to grasp, or for a system that is easy to understand but imprecise, with the risk of demotivating potential partners? In the longer run, as some Wikimedians have already suggested, it will be helpful if information templates and other user interface elements on Wikimedia Commons provide information and clues that make the distinction intuitively clear to laypeople.
New adventures in the land of federation, or: where should certain data be stored?
Structured Data on Commons is built on the concept of federation. What does this mean?
In a technical sense, a federated database system is a management system where multiple autonomous databases work together in a single, so-called federated, database. Wikibase Federation is implemented for Structured Data on Wikimedia Commons: it makes it possible to use entities (Items and Properties) defined on one Wikibase repository (i.e., Wikidata) on another Wikibase repository (i.e., Wikimedia Commons).
Structured Data on Commons – Project glossary
Wikimedia Commons is now Wikimedia’s first federated ‘structured data sister’ of Wikidata that is used very intensively – and we are starting to see some peculiar challenges around this: data lives in different places, but needs to make sense together.
Related to the above-mentioned issue of ‘work versus file’, GLAM-focused Wikimedians who work with structured data on Wikimedia Commons now face a new challenge: should the (separate) information about creative works be stored on Wikidata, or on Wikimedia Commons?
In February 2020, Wikidata contains nearly 2 million data items for artworks. Since Wikidata was founded in 2012, quite a few GLAM-Wiki projects have engaged with Wikidata as a general Linked Open Data storage base. To name just a few examples: Wikidata contains data about works in the collections of Brazilian and Flemish museums, of the National Library of Wales and the Metropolitan Museum of Art… Volunteer-driven projects like the Sum of All Paintings and Wiki Loves Monuments have also curated hundreds of thousands of Wikidata items of creative works and buildings. Wikimedia Commons volunteers have now started to connect files on Wikimedia Commons to these works on Wikidata, using structured data. The general process for Wiki Loves Monuments has recently been documented, and input is welcome.

Rietveld Schröder House in Utrecht, photo by ErikHonig, CC BY-SA 3.0 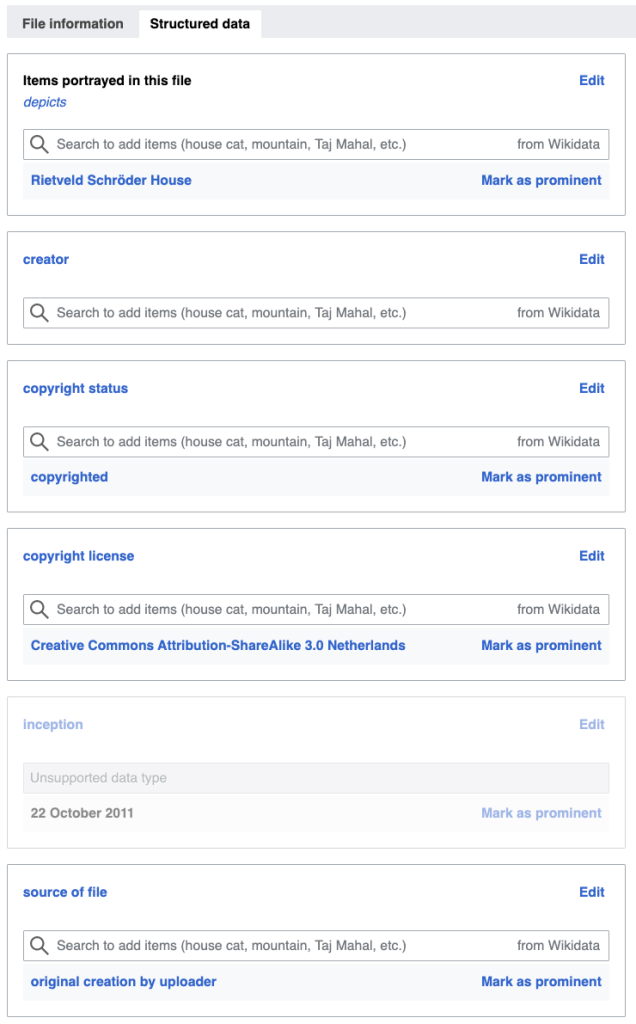
Some of the structured data of this photo, as stored on Wikimedia Commons. 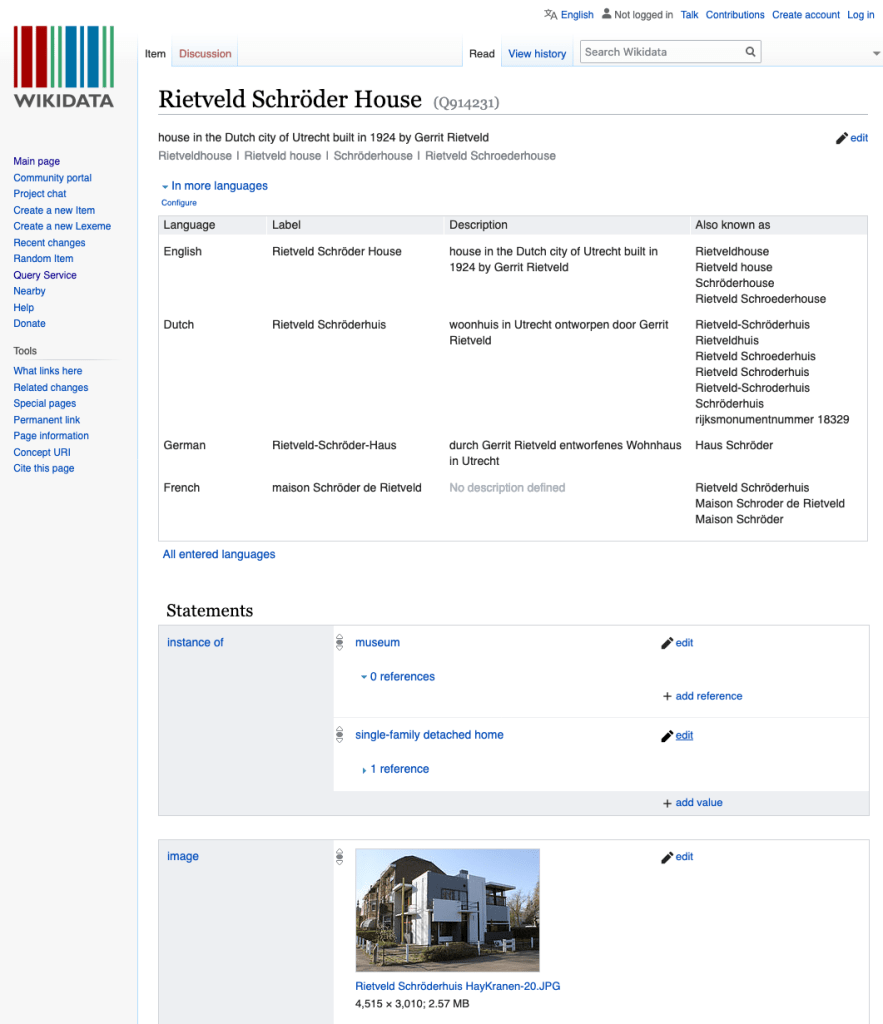
… which points to data about the building itself, as stored on Wikidata.
{kind=link}

Jakob Smits: Frederick Coburn (1896), collection Jakob Smitsmuseum, Public Domain 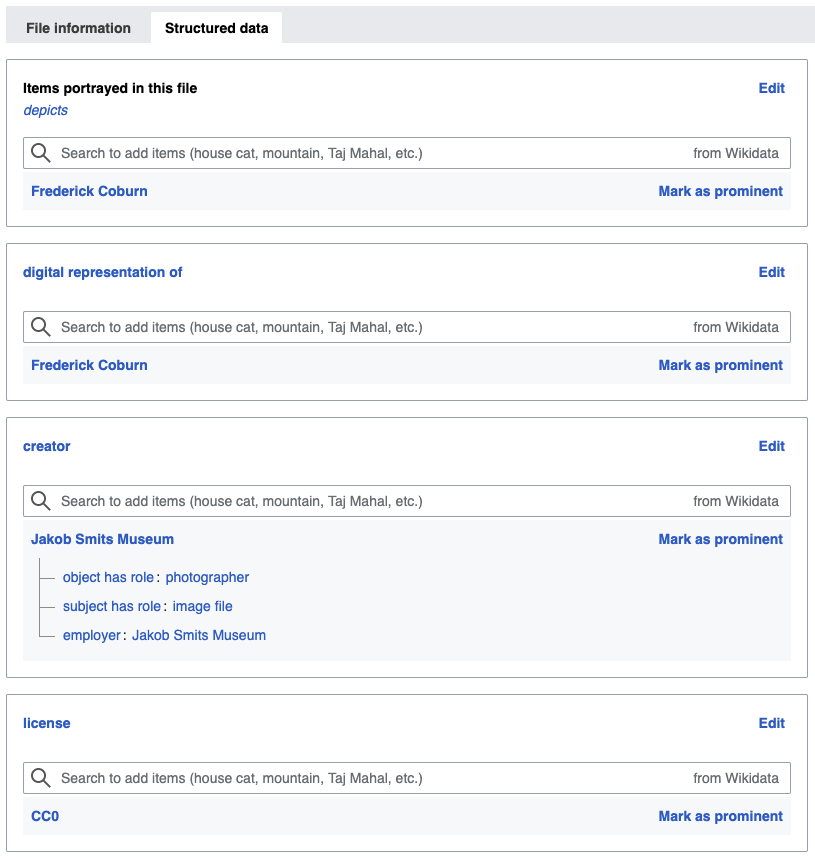
Structured data of this image, as stored on Wikimedia Commons 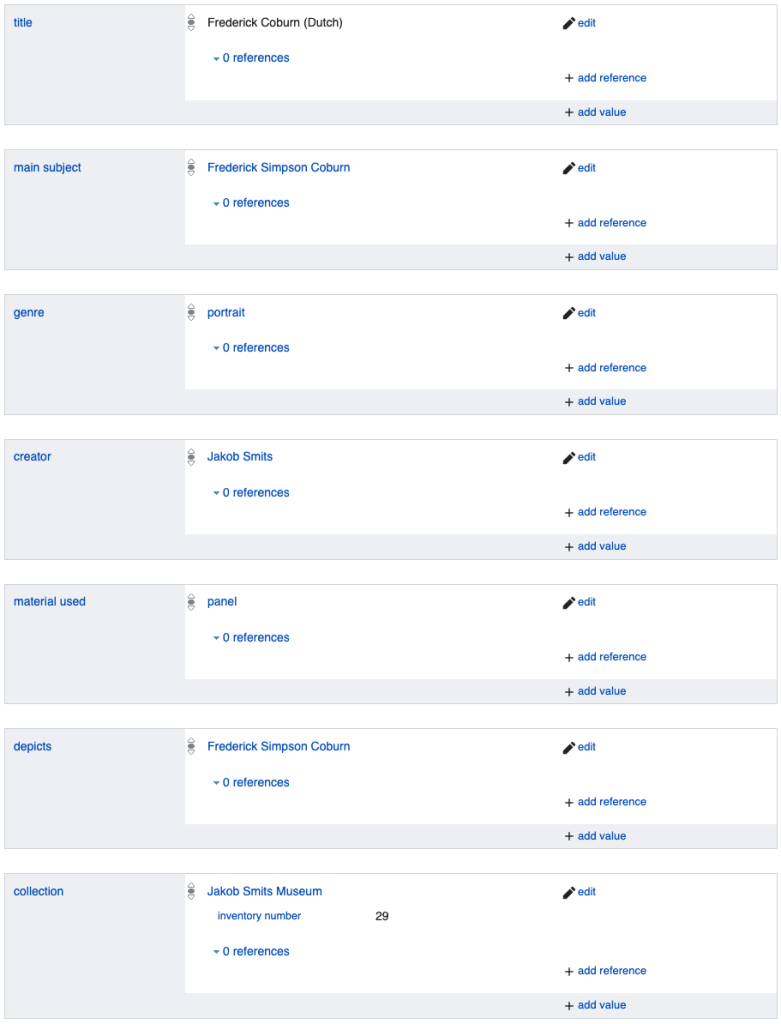
… which points to data about the painting, as stored on Wikidata.
{kind=link}

{kind=link}
But does this mean that every single creative work with a file on Wikimedia Commons should have its own Wikidata item? What about individual relief sculptures in temple façades, individual pages or even illustrations in books, or seemingly ‘unglamorous’ objects like ceramics shards and pieces of fabric? Is Wikidata’s infrastructure technically able to store items for all these millions of works? And does it make sense?
A related question: what would be the advantages and disadvantages of ‘data duplication’? In the example of the portrait painting of Frederick Coburn above: what would it mean if information about the creator, creation date and sitter of the painting would also be available on Wikimedia Commons? This would certainly help to make this image directly discoverable on Wikimedia Commons (see below). But it also brings risks of data that is unclear and out of sync, with mistakes on either side that are less easy to discover, and two communities maintaining similar data in parallel.
The structured data-related GLAM pilot projects that I have mentored have indeed gone the ‘creative work on Wikidata’ route. However, it will be very useful to learn from other GLAM-Wiki projects that explore how to keep all structured data on Commons, not creating separate Wikidata items for creative works. Dominic Byrd-McDevitt, Data Fellow at the Digital Public Library of America is already looking into that option. At the time of writing this blog post, he is experimenting how to do that. Input is certainly very welcome. If, as a reader of this blog post, you (have) run such an experiment yourself, please list it on the overview of GLAM projects using Structured Data on Commons, in order to help and inspire others.
Technically, this ‘federated’ situation also poses interesting challenges around upload and discovery. If someone searches for images of, say, the Hindu deity Ganesha on Wikimedia Commons, it would be great if they also find results of images that depict a sculpture of Ganesha, even if the ‘depicts:Ganesha’ statement is on Wikidata, not on Commons. And how to build an easy-to-understand (batch) upload tool that adds the right data in the right place in a federated way?
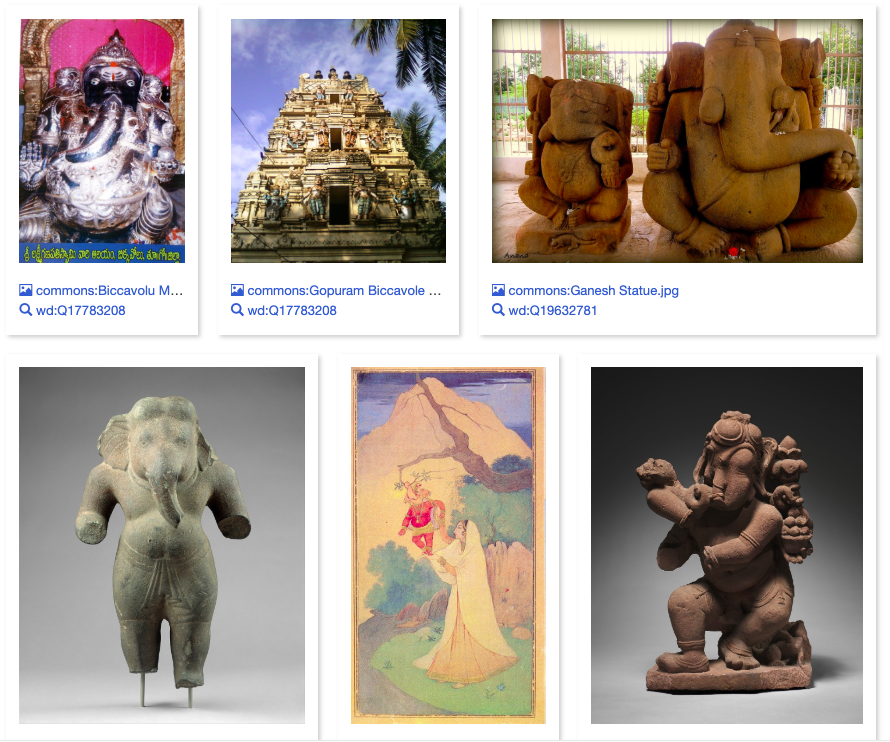
These open questions and challenges are probably typical for a federated, distributed web of data at large. As the Wikimedia movement hopefully grows to become more diverse, we may pose these kinds of questions more often. What if more Wikimedia projects become powered by federated structured data? Wikibase, the software behind Wikidata, is increasingly used by institutions around the world, and this community is discussing the challenges around federation as well.
What’s next?
Millions of files on Wikimedia Commons are described with some structured data already; community members are adding more structured data to files every day. With each new GLAM-Wiki project, we can learn more as a community, and inspire each other. Please report on your projects in the This Month in GLAM newsletter, share your insights, and feel free to list your initiatives in the overview page of Structured Data on Commons and GLAM projects. Document and discuss your experiences in data modeling. You can ask questions on the dedicated Structured Data on Commons talk pages: general talk page, data modeling.
In order to help GLAM staff and Wikimedia communities get started, an introduction to structured data for GLAM-Wiki is now available on meta.wikimedia.org (work in progress!). Everyone is warmly invited to extend and improve this documentation, translate it, add examples to it…
And finally, GLAM-Wiki projects need solid technical infrastructure to contribute content to Wikimedia projects at scale – now also with support for structured data. Up until present, GLAM-Wiki collaborations around the world have flourished thanks to many dedicated batch upload, statistics and curation tools built by Wikimedia volunteers. In order to make this technical infrastructure more sustainable, Wikimedia Sverige (WMSE) is currently growing its capacity to become a GLAM Hub for the Wikimedia movement, and this includes the development of GLAM-Wiki tools that support structured data. If you want to stay informed, keep an eye on the meta.wikimedia.org page about this initiative!
This is the last of a series of blog posts on Wikimedia Space about GLAM pilot projects with Structured Data on Wikimedia Commons. Earlier posts are:
- Introducing ISA – A cool tool for adding structured data on Commons by Isla Haddow-Flood
- How we helped a small art museum to increase the impact of its collections, with Wikimedia projects and structured data by Sandra Fauconnier
- How can Structured Data on Commons, Wikidata, and Wikisource walk hand in hand? A pilot project with Punjabi Qisse by Satdeep Gill
- Data Roundtripping: A new frontier for GLAM-Wiki collaborations by Sandra Fauconnier
- Connecting the work of three generations of decorative artists, with structured data by Sandra Fauconnier
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation